Merge pull request #25256 from BerriAI/litellm_ishaan_april6
Litellm ishaan april6
This commit is contained in:
commit
1c128a86b8
40
.github/scripts/close_duplicate_issues.py
vendored
40
.github/scripts/close_duplicate_issues.py
vendored
@ -42,7 +42,9 @@ def gh(*args: str) -> str:
|
||||
def fetch_open_issues(repo: str | None) -> list[dict]:
|
||||
"""Fetch all open issues (excluding PRs) via gh api --paginate."""
|
||||
if repo:
|
||||
endpoint = f"repos/{repo}/issues?state=open&per_page=100&sort=created&direction=asc"
|
||||
endpoint = (
|
||||
f"repos/{repo}/issues?state=open&per_page=100&sort=created&direction=asc"
|
||||
)
|
||||
else:
|
||||
endpoint = "repos/{owner}/{repo}/issues?state=open&per_page=100&sort=created&direction=asc"
|
||||
cmd = ["api", "--paginate", endpoint]
|
||||
@ -71,7 +73,9 @@ def close_as_duplicate(
|
||||
repo_args = ["--repo", repo] if repo else []
|
||||
|
||||
if dry_run:
|
||||
print(f" [DRY RUN] Would close #{issue_number} as duplicate of #{duplicate_of}")
|
||||
print(
|
||||
f" [DRY RUN] Would close #{issue_number} as duplicate of #{duplicate_of}"
|
||||
)
|
||||
return
|
||||
|
||||
# Add comment
|
||||
@ -115,7 +119,9 @@ def find_duplicate(
|
||||
return None
|
||||
|
||||
|
||||
def scan_all(issues: list[dict], threshold: float, repo: str | None, dry_run: bool) -> int:
|
||||
def scan_all(
|
||||
issues: list[dict], threshold: float, repo: str | None, dry_run: bool
|
||||
) -> int:
|
||||
"""Compare every issue against all older issues. Returns count of duplicates found."""
|
||||
# Sort oldest first
|
||||
issues.sort(key=lambda i: i["number"])
|
||||
@ -144,7 +150,11 @@ def scan_all(issues: list[dict], threshold: float, repo: str | None, dry_run: bo
|
||||
|
||||
|
||||
def check_single(
|
||||
issue_number: int, issues: list[dict], threshold: float, repo: str | None, dry_run: bool
|
||||
issue_number: int,
|
||||
issues: list[dict],
|
||||
threshold: float,
|
||||
repo: str | None,
|
||||
dry_run: bool,
|
||||
) -> bool:
|
||||
"""Check a single issue against all older open issues. Returns True if duplicate found."""
|
||||
target = None
|
||||
@ -178,13 +188,23 @@ def check_single(
|
||||
|
||||
|
||||
def main() -> None:
|
||||
parser = argparse.ArgumentParser(description="Detect and close duplicate GitHub issues")
|
||||
parser = argparse.ArgumentParser(
|
||||
description="Detect and close duplicate GitHub issues"
|
||||
)
|
||||
mode = parser.add_mutually_exclusive_group(required=True)
|
||||
mode.add_argument("--scan", action="store_true", help="Scan all open issues")
|
||||
mode.add_argument("--issue-number", type=int, help="Check a single issue number")
|
||||
parser.add_argument("--threshold", type=float, default=0.85, help="Similarity threshold (0-1)")
|
||||
parser.add_argument("--close", action="store_true", help="Actually close duplicates (default is dry-run)")
|
||||
parser.add_argument("--repo", type=str, help="Repository (owner/repo). Auto-detected if omitted.")
|
||||
parser.add_argument(
|
||||
"--threshold", type=float, default=0.85, help="Similarity threshold (0-1)"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--close",
|
||||
action="store_true",
|
||||
help="Actually close duplicates (default is dry-run)",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--repo", type=str, help="Repository (owner/repo). Auto-detected if omitted."
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
dry_run = not args.close
|
||||
@ -200,7 +220,9 @@ def main() -> None:
|
||||
count = scan_all(issues, args.threshold, args.repo, dry_run)
|
||||
print(f"\nTotal duplicates {'found' if dry_run else 'closed'}: {count}")
|
||||
else:
|
||||
found = check_single(args.issue_number, issues, args.threshold, args.repo, dry_run)
|
||||
found = check_single(
|
||||
args.issue_number, issues, args.threshold, args.repo, dry_run
|
||||
)
|
||||
sys.exit(0 if found else 0) # Always exit 0; finding no dup is not an error
|
||||
|
||||
|
||||
|
||||
20
.github/scripts/scan_keywords.py
vendored
20
.github/scripts/scan_keywords.py
vendored
@ -67,14 +67,13 @@ def send_webhook(webhook_url: str, payload: dict) -> None:
|
||||
def _excerpt(text: str, max_len: int = 400) -> str:
|
||||
if not text:
|
||||
return ""
|
||||
|
||||
|
||||
# Keep original formatting
|
||||
if len(text) <= max_len:
|
||||
return text
|
||||
return text[: max_len - 1] + "…"
|
||||
|
||||
|
||||
|
||||
def main() -> int:
|
||||
event = read_event_payload()
|
||||
if not event:
|
||||
@ -87,8 +86,19 @@ def main() -> int:
|
||||
|
||||
# Keywords from env or defaults
|
||||
keywords_env = os.environ.get("KEYWORDS", "")
|
||||
default_keywords = ["azure", "openai", "bedrock", "vertexai", "vertex ai", "anthropic"]
|
||||
keywords = [k.strip() for k in keywords_env.split(",")] if keywords_env else default_keywords
|
||||
default_keywords = [
|
||||
"azure",
|
||||
"openai",
|
||||
"bedrock",
|
||||
"vertexai",
|
||||
"vertex ai",
|
||||
"anthropic",
|
||||
]
|
||||
keywords = (
|
||||
[k.strip() for k in keywords_env.split(",")]
|
||||
if keywords_env
|
||||
else default_keywords
|
||||
)
|
||||
|
||||
matches = detect_keywords(combined_text, keywords)
|
||||
found = bool(matches)
|
||||
@ -129,5 +139,3 @@ def main() -> int:
|
||||
|
||||
if __name__ == "__main__":
|
||||
raise SystemExit(main())
|
||||
|
||||
|
||||
|
||||
@ -17,7 +17,9 @@ def create_migration(migration_name: str = None):
|
||||
try:
|
||||
# Get paths
|
||||
root_dir = Path(__file__).parent.parent
|
||||
migrations_dir = root_dir / "litellm-proxy-extras" / "litellm_proxy_extras" / "migrations"
|
||||
migrations_dir = (
|
||||
root_dir / "litellm-proxy-extras" / "litellm_proxy_extras" / "migrations"
|
||||
)
|
||||
schema_path = root_dir / "schema.prisma"
|
||||
|
||||
# Create temporary PostgreSQL database
|
||||
|
||||
@ -24,24 +24,26 @@ async def interactive_chat_with_mcp():
|
||||
Interactive CLI chat with the agent and MCP server
|
||||
"""
|
||||
config = Config()
|
||||
|
||||
|
||||
# Configure Anthropic SDK to point to LiteLLM gateway
|
||||
litellm_base_url = setup_litellm_env(config)
|
||||
|
||||
|
||||
# Fetch available models from proxy
|
||||
available_models = await fetch_available_models(litellm_base_url, config.LITELLM_API_KEY)
|
||||
|
||||
available_models = await fetch_available_models(
|
||||
litellm_base_url, config.LITELLM_API_KEY
|
||||
)
|
||||
|
||||
current_model = config.LITELLM_MODEL
|
||||
|
||||
|
||||
# MCP server configuration
|
||||
mcp_server_url = f"{litellm_base_url}/mcp/deepwiki2"
|
||||
use_mcp = os.getenv("USE_MCP", "true").lower() == "true"
|
||||
|
||||
|
||||
if not use_mcp:
|
||||
print("⚠️ MCP disabled via USE_MCP=false")
|
||||
|
||||
|
||||
print_header(litellm_base_url, current_model, has_mcp=use_mcp)
|
||||
|
||||
|
||||
while True:
|
||||
# Configure agent options
|
||||
if use_mcp:
|
||||
@ -58,7 +60,7 @@ async def interactive_chat_with_mcp():
|
||||
"url": mcp_server_url,
|
||||
"headers": {
|
||||
"Authorization": f"Bearer {config.LITELLM_API_KEY}"
|
||||
}
|
||||
},
|
||||
}
|
||||
},
|
||||
)
|
||||
@ -78,12 +80,12 @@ async def interactive_chat_with_mcp():
|
||||
model=current_model,
|
||||
max_turns=50,
|
||||
)
|
||||
|
||||
|
||||
# Create agent client
|
||||
try:
|
||||
async with ClaudeSDKClient(options=options) as client:
|
||||
conversation_active = True
|
||||
|
||||
|
||||
while conversation_active:
|
||||
# Get user input
|
||||
try:
|
||||
@ -91,34 +93,36 @@ async def interactive_chat_with_mcp():
|
||||
except (EOFError, KeyboardInterrupt):
|
||||
print("\n\n👋 Goodbye!")
|
||||
return
|
||||
|
||||
|
||||
# Handle commands
|
||||
if user_input.lower() in ['quit', 'exit']:
|
||||
if user_input.lower() in ["quit", "exit"]:
|
||||
print("\n👋 Goodbye!")
|
||||
return
|
||||
|
||||
if user_input.lower() == 'clear':
|
||||
|
||||
if user_input.lower() == "clear":
|
||||
print("\n🔄 Starting new conversation...\n")
|
||||
conversation_active = False
|
||||
continue
|
||||
|
||||
if user_input.lower() == 'models':
|
||||
|
||||
if user_input.lower() == "models":
|
||||
handle_model_list(available_models, current_model)
|
||||
continue
|
||||
|
||||
if user_input.lower() == 'model':
|
||||
new_model, should_restart = handle_model_switch(available_models, current_model)
|
||||
|
||||
if user_input.lower() == "model":
|
||||
new_model, should_restart = handle_model_switch(
|
||||
available_models, current_model
|
||||
)
|
||||
if should_restart:
|
||||
current_model = new_model
|
||||
conversation_active = False
|
||||
continue
|
||||
|
||||
|
||||
if not user_input:
|
||||
continue
|
||||
|
||||
|
||||
# Stream response from agent
|
||||
await stream_response(client, user_input)
|
||||
|
||||
|
||||
except Exception as e:
|
||||
print(f"\n❌ Error creating agent client: {e}")
|
||||
print("This might be an MCP configuration issue. Try running without MCP:")
|
||||
|
||||
@ -8,13 +8,13 @@ import httpx
|
||||
|
||||
class Config:
|
||||
"""Configuration for LiteLLM Gateway connection"""
|
||||
|
||||
|
||||
# LiteLLM proxy URL (default to local instance)
|
||||
LITELLM_PROXY_URL = os.getenv("LITELLM_PROXY_URL", "http://localhost:4000")
|
||||
|
||||
|
||||
# LiteLLM API key (master key or virtual key)
|
||||
LITELLM_API_KEY = os.getenv("LITELLM_API_KEY", "sk-1234")
|
||||
|
||||
|
||||
# Model name as configured in LiteLLM (e.g., "bedrock-claude-sonnet-4", "gpt-4", etc.)
|
||||
LITELLM_MODEL = os.getenv("LITELLM_MODEL", "bedrock-claude-sonnet-4.5")
|
||||
|
||||
@ -28,7 +28,7 @@ async def fetch_available_models(base_url: str, api_key: str) -> list[str]:
|
||||
response = await client.get(
|
||||
f"{base_url}/models",
|
||||
headers={"Authorization": f"Bearer {api_key}"},
|
||||
timeout=10.0
|
||||
timeout=10.0,
|
||||
)
|
||||
response.raise_for_status()
|
||||
data = response.json()
|
||||
@ -50,7 +50,7 @@ def setup_litellm_env(config: Config):
|
||||
"""
|
||||
Configure environment variables to point Agent SDK to LiteLLM
|
||||
"""
|
||||
litellm_base_url = config.LITELLM_PROXY_URL.rstrip('/')
|
||||
litellm_base_url = config.LITELLM_PROXY_URL.rstrip("/")
|
||||
os.environ["ANTHROPIC_BASE_URL"] = litellm_base_url
|
||||
os.environ["ANTHROPIC_API_KEY"] = config.LITELLM_API_KEY
|
||||
return litellm_base_url
|
||||
@ -87,10 +87,12 @@ def handle_model_list(available_models: list[str], current_model: str):
|
||||
print(f" {marker} {i}. {model}")
|
||||
|
||||
|
||||
def handle_model_switch(available_models: list[str], current_model: str) -> tuple[str, bool]:
|
||||
def handle_model_switch(
|
||||
available_models: list[str], current_model: str
|
||||
) -> tuple[str, bool]:
|
||||
"""
|
||||
Handle model switching
|
||||
|
||||
|
||||
Returns:
|
||||
tuple: (new_model, should_restart_conversation)
|
||||
"""
|
||||
@ -98,7 +100,7 @@ def handle_model_switch(available_models: list[str], current_model: str) -> tupl
|
||||
for i, model in enumerate(available_models, 1):
|
||||
marker = "✓" if model == current_model else " "
|
||||
print(f" {marker} {i}. {model}")
|
||||
|
||||
|
||||
try:
|
||||
choice = input("\nEnter number (or press Enter to cancel): ").strip()
|
||||
if choice:
|
||||
@ -112,7 +114,7 @@ def handle_model_switch(available_models: list[str], current_model: str) -> tupl
|
||||
print("❌ Invalid choice")
|
||||
except (ValueError, IndexError):
|
||||
print("❌ Invalid input")
|
||||
|
||||
|
||||
return current_model, False
|
||||
|
||||
|
||||
@ -120,41 +122,43 @@ async def stream_response(client, user_input: str):
|
||||
"""
|
||||
Stream response from the agent
|
||||
"""
|
||||
print("\n🤖 Assistant: ", end='', flush=True)
|
||||
|
||||
print("\n🤖 Assistant: ", end="", flush=True)
|
||||
|
||||
try:
|
||||
await client.query(user_input)
|
||||
|
||||
|
||||
# Show loading indicator
|
||||
print("⏳ thinking...", end='', flush=True)
|
||||
|
||||
print("⏳ thinking...", end="", flush=True)
|
||||
|
||||
# Stream the response
|
||||
first_chunk = True
|
||||
async for msg in client.receive_response():
|
||||
# Clear loading indicator on first message
|
||||
if first_chunk:
|
||||
print("\r🤖 Assistant: ", end='', flush=True)
|
||||
print("\r🤖 Assistant: ", end="", flush=True)
|
||||
first_chunk = False
|
||||
|
||||
|
||||
# Handle different message types
|
||||
if hasattr(msg, 'type'):
|
||||
if msg.type == 'content_block_delta':
|
||||
if hasattr(msg, "type"):
|
||||
if msg.type == "content_block_delta":
|
||||
# Streaming text delta
|
||||
if hasattr(msg, 'delta') and hasattr(msg.delta, 'text'):
|
||||
print(msg.delta.text, end='', flush=True)
|
||||
elif msg.type == 'content_block_start':
|
||||
if hasattr(msg, "delta") and hasattr(msg.delta, "text"):
|
||||
print(msg.delta.text, end="", flush=True)
|
||||
elif msg.type == "content_block_start":
|
||||
# Start of content block
|
||||
if hasattr(msg, 'content_block') and hasattr(msg.content_block, 'text'):
|
||||
print(msg.content_block.text, end='', flush=True)
|
||||
|
||||
if hasattr(msg, "content_block") and hasattr(
|
||||
msg.content_block, "text"
|
||||
):
|
||||
print(msg.content_block.text, end="", flush=True)
|
||||
|
||||
# Fallback to original content handling
|
||||
if hasattr(msg, 'content'):
|
||||
if hasattr(msg, "content"):
|
||||
for content_block in msg.content:
|
||||
if hasattr(content_block, 'text'):
|
||||
print(content_block.text, end='', flush=True)
|
||||
|
||||
if hasattr(content_block, "text"):
|
||||
print(content_block.text, end="", flush=True)
|
||||
|
||||
print() # New line after response
|
||||
|
||||
|
||||
except Exception as e:
|
||||
print(f"\r\n❌ Error: {e}")
|
||||
print("Please check your LiteLLM gateway is running and configured correctly.")
|
||||
|
||||
@ -24,17 +24,19 @@ async def interactive_chat():
|
||||
Interactive CLI chat with the agent
|
||||
"""
|
||||
config = Config()
|
||||
|
||||
|
||||
# Configure Anthropic SDK to point to LiteLLM gateway
|
||||
litellm_base_url = setup_litellm_env(config)
|
||||
|
||||
|
||||
# Fetch available models from proxy
|
||||
available_models = await fetch_available_models(litellm_base_url, config.LITELLM_API_KEY)
|
||||
|
||||
available_models = await fetch_available_models(
|
||||
litellm_base_url, config.LITELLM_API_KEY
|
||||
)
|
||||
|
||||
current_model = config.LITELLM_MODEL
|
||||
|
||||
|
||||
print_header(litellm_base_url, current_model)
|
||||
|
||||
|
||||
while True:
|
||||
# Configure agent options for each conversation
|
||||
options = ClaudeAgentOptions(
|
||||
@ -42,11 +44,11 @@ async def interactive_chat():
|
||||
model=current_model,
|
||||
max_turns=50,
|
||||
)
|
||||
|
||||
|
||||
# Create agent client
|
||||
async with ClaudeSDKClient(options=options) as client:
|
||||
conversation_active = True
|
||||
|
||||
|
||||
while conversation_active:
|
||||
# Get user input
|
||||
try:
|
||||
@ -54,31 +56,33 @@ async def interactive_chat():
|
||||
except (EOFError, KeyboardInterrupt):
|
||||
print("\n\n👋 Goodbye!")
|
||||
return
|
||||
|
||||
|
||||
# Handle commands
|
||||
if user_input.lower() in ['quit', 'exit']:
|
||||
if user_input.lower() in ["quit", "exit"]:
|
||||
print("\n👋 Goodbye!")
|
||||
return
|
||||
|
||||
if user_input.lower() == 'clear':
|
||||
|
||||
if user_input.lower() == "clear":
|
||||
print("\n🔄 Starting new conversation...\n")
|
||||
conversation_active = False
|
||||
continue
|
||||
|
||||
if user_input.lower() == 'models':
|
||||
|
||||
if user_input.lower() == "models":
|
||||
handle_model_list(available_models, current_model)
|
||||
continue
|
||||
|
||||
if user_input.lower() == 'model':
|
||||
new_model, should_restart = handle_model_switch(available_models, current_model)
|
||||
|
||||
if user_input.lower() == "model":
|
||||
new_model, should_restart = handle_model_switch(
|
||||
available_models, current_model
|
||||
)
|
||||
if should_restart:
|
||||
current_model = new_model
|
||||
conversation_active = False
|
||||
continue
|
||||
|
||||
|
||||
if not user_input:
|
||||
continue
|
||||
|
||||
|
||||
# Stream response from agent
|
||||
await stream_response(client, user_input)
|
||||
|
||||
|
||||
@ -11,15 +11,15 @@ BEDROCK_BATCH_MODEL = "bedrock/batch-anthropic.claude-3-5-sonnet-20240620-v1:0"
|
||||
batch_input_file = client.files.create(
|
||||
file=open("./bedrock_batch_completions.jsonl", "rb"),
|
||||
purpose="batch",
|
||||
extra_body={"target_model_names": BEDROCK_BATCH_MODEL}
|
||||
extra_body={"target_model_names": BEDROCK_BATCH_MODEL},
|
||||
)
|
||||
print(batch_input_file)
|
||||
|
||||
# Create batch
|
||||
batch = client.batches.create(
|
||||
batch = client.batches.create(
|
||||
input_file_id=batch_input_file.id,
|
||||
endpoint="/v1/chat/completions",
|
||||
completion_window="24h",
|
||||
metadata={"description": "Test batch job"},
|
||||
)
|
||||
print(batch)
|
||||
print(batch)
|
||||
|
||||
@ -8,6 +8,7 @@ in your Python scripts after running `litellm-proxy login`.
|
||||
|
||||
from textwrap import indent
|
||||
import litellm
|
||||
|
||||
LITELLM_BASE_URL = "http://localhost:4000/"
|
||||
|
||||
|
||||
@ -15,38 +16,38 @@ def main():
|
||||
"""Using CLI token with LiteLLM SDK"""
|
||||
print("🚀 Using CLI Token with LiteLLM SDK")
|
||||
print("=" * 40)
|
||||
#litellm._turn_on_debug()
|
||||
|
||||
# litellm._turn_on_debug()
|
||||
|
||||
# Get the CLI token
|
||||
api_key = litellm.get_litellm_gateway_api_key()
|
||||
|
||||
|
||||
if not api_key:
|
||||
print("❌ No CLI token found. Please run 'litellm-proxy login' first.")
|
||||
return
|
||||
|
||||
|
||||
print("✅ Found CLI token.")
|
||||
|
||||
available_models = litellm.get_valid_models(
|
||||
check_provider_endpoint=True,
|
||||
custom_llm_provider="litellm_proxy",
|
||||
api_key=api_key,
|
||||
api_base=LITELLM_BASE_URL
|
||||
api_base=LITELLM_BASE_URL,
|
||||
)
|
||||
|
||||
|
||||
print("✅ Available models:")
|
||||
if available_models:
|
||||
for i, model in enumerate(available_models, 1):
|
||||
print(f" {i:2d}. {model}")
|
||||
else:
|
||||
print(" No models available")
|
||||
|
||||
|
||||
# Use with LiteLLM
|
||||
try:
|
||||
response = litellm.completion(
|
||||
model="litellm_proxy/gemini/gemini-2.5-flash",
|
||||
messages=[{"role": "user", "content": "Hello from CLI token!"}],
|
||||
api_key=api_key,
|
||||
base_url=LITELLM_BASE_URL
|
||||
base_url=LITELLM_BASE_URL,
|
||||
)
|
||||
print(f"✅ LLM Response: {response.model_dump_json(indent=4)}")
|
||||
except Exception as e:
|
||||
@ -55,7 +56,7 @@ def main():
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
||||
|
||||
print("\n💡 Tips:")
|
||||
print("1. Run 'litellm-proxy login' to authenticate first")
|
||||
print("2. Replace 'https://your-proxy.com' with your actual proxy URL")
|
||||
|
||||
@ -3,11 +3,12 @@ Use LiteLLM Proxy MCP Gateway to call MCP tools.
|
||||
|
||||
When using LiteLLM Proxy, you can use the same MCP tools across all your LLM providers.
|
||||
"""
|
||||
|
||||
import openai
|
||||
|
||||
client = openai.OpenAI(
|
||||
api_key="sk-1234", # paste your litellm proxy api key here
|
||||
base_url="http://localhost:4000" # paste your litellm proxy base url here
|
||||
api_key="sk-1234", # paste your litellm proxy api key here
|
||||
base_url="http://localhost:4000", # paste your litellm proxy base url here
|
||||
)
|
||||
print("Making API request to Responses API with MCP tools")
|
||||
|
||||
@ -17,7 +18,7 @@ response = client.responses.create(
|
||||
{
|
||||
"role": "user",
|
||||
"content": "give me TLDR of what BerriAI/litellm repo is about",
|
||||
"type": "message"
|
||||
"type": "message",
|
||||
}
|
||||
],
|
||||
tools=[
|
||||
@ -25,11 +26,11 @@ response = client.responses.create(
|
||||
"type": "mcp",
|
||||
"server_label": "litellm",
|
||||
"server_url": "litellm_proxy",
|
||||
"require_approval": "never"
|
||||
"require_approval": "never",
|
||||
}
|
||||
],
|
||||
stream=True,
|
||||
tool_choice="required"
|
||||
tool_choice="required",
|
||||
)
|
||||
|
||||
for chunk in response:
|
||||
|
||||
@ -40,8 +40,10 @@ class InMemorySecretManager(CustomSecretManager):
|
||||
) -> Optional[str]:
|
||||
"""Read secret synchronously"""
|
||||
from litellm._logging import verbose_proxy_logger
|
||||
|
||||
verbose_proxy_logger.info(f"CUSTOM SECRET MANAGER: LOOKING FOR SECRET: {secret_name}")
|
||||
|
||||
verbose_proxy_logger.info(
|
||||
f"CUSTOM SECRET MANAGER: LOOKING FOR SECRET: {secret_name}"
|
||||
)
|
||||
value = self.secrets.get(secret_name)
|
||||
verbose_proxy_logger.info(f"CUSTOM SECRET MANAGER: READ SECRET: {value}")
|
||||
return value
|
||||
@ -76,4 +78,3 @@ class InMemorySecretManager(CustomSecretManager):
|
||||
del self.secrets[secret_name]
|
||||
return {"status": "deleted", "secret_name": secret_name}
|
||||
return {"status": "not_found", "secret_name": secret_name}
|
||||
|
||||
|
||||
@ -5,6 +5,7 @@ This example shows how to use LiveKit's xAI realtime plugin through LiteLLM prox
|
||||
LiteLLM acts as a unified interface, allowing you to switch between xAI, OpenAI,
|
||||
and Azure realtime APIs without changing your agent code.
|
||||
"""
|
||||
|
||||
import asyncio
|
||||
import json
|
||||
import os
|
||||
@ -23,71 +24,79 @@ async def run_voice_agent():
|
||||
2. Sends a user message
|
||||
3. Streams back the response
|
||||
"""
|
||||
|
||||
|
||||
url = f"ws://{PROXY_URL.replace('http://', '').replace('https://', '')}/v1/realtime?model={MODEL}"
|
||||
headers = {"Authorization": f"Bearer {API_KEY}"}
|
||||
|
||||
|
||||
print(f"🎙️ Connecting to voice agent...")
|
||||
print(f" Model: {MODEL}")
|
||||
print(f" Proxy: {PROXY_URL}")
|
||||
print()
|
||||
|
||||
|
||||
async with websockets.connect(url, additional_headers=headers) as ws:
|
||||
# Receive initial connection event
|
||||
initial = json.loads(await ws.recv())
|
||||
print(f"✅ Connected! Event: {initial['type']}\n")
|
||||
|
||||
|
||||
# Get user input
|
||||
user_message = input("💬 Your message: ").strip()
|
||||
if not user_message:
|
||||
user_message = "Tell me a fun fact about AI!"
|
||||
|
||||
|
||||
print(f"\n🤖 Sending to {MODEL}...\n")
|
||||
|
||||
|
||||
# Send user message
|
||||
await ws.send(json.dumps({
|
||||
"type": "conversation.item.create",
|
||||
"item": {
|
||||
"type": "message",
|
||||
"role": "user",
|
||||
"content": [{"type": "input_text", "text": user_message}]
|
||||
}
|
||||
}))
|
||||
|
||||
await ws.send(
|
||||
json.dumps(
|
||||
{
|
||||
"type": "conversation.item.create",
|
||||
"item": {
|
||||
"type": "message",
|
||||
"role": "user",
|
||||
"content": [{"type": "input_text", "text": user_message}],
|
||||
},
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Request response
|
||||
await ws.send(json.dumps({
|
||||
"type": "response.create",
|
||||
"response": {"modalities": ["text", "audio"]}
|
||||
}))
|
||||
|
||||
await ws.send(
|
||||
json.dumps(
|
||||
{
|
||||
"type": "response.create",
|
||||
"response": {"modalities": ["text", "audio"]},
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
# Stream response
|
||||
print("🎤 Response: ", end='', flush=True)
|
||||
print("🎤 Response: ", end="", flush=True)
|
||||
transcript = []
|
||||
|
||||
|
||||
try:
|
||||
while True:
|
||||
msg = await asyncio.wait_for(ws.recv(), timeout=15.0)
|
||||
event = json.loads(msg)
|
||||
|
||||
|
||||
# Capture transcript deltas
|
||||
if event['type'] == 'response.output_audio_transcript.delta':
|
||||
delta = event.get('delta', '')
|
||||
if event["type"] == "response.output_audio_transcript.delta":
|
||||
delta = event.get("delta", "")
|
||||
if delta:
|
||||
print(delta, end='', flush=True)
|
||||
print(delta, end="", flush=True)
|
||||
transcript.append(delta)
|
||||
|
||||
|
||||
# Done when response completes
|
||||
elif event['type'] == 'response.done':
|
||||
elif event["type"] == "response.done":
|
||||
break
|
||||
|
||||
|
||||
except asyncio.TimeoutError:
|
||||
pass
|
||||
|
||||
|
||||
print("\n")
|
||||
|
||||
|
||||
if transcript:
|
||||
print(f"✅ Complete response: {''.join(transcript)}")
|
||||
|
||||
|
||||
await ws.close()
|
||||
|
||||
|
||||
@ -97,7 +106,7 @@ def main():
|
||||
print("LiveKit xAI Voice Agent via LiteLLM Proxy")
|
||||
print("=" * 70)
|
||||
print()
|
||||
|
||||
|
||||
try:
|
||||
asyncio.run(run_voice_agent())
|
||||
except KeyboardInterrupt:
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
import base64
|
||||
from openai import OpenAI
|
||||
import time
|
||||
client = OpenAI(
|
||||
base_url="http://0.0.0.0:4001",
|
||||
api_key="sk-1234"
|
||||
)
|
||||
|
||||
client = OpenAI(base_url="http://0.0.0.0:4001", api_key="sk-1234")
|
||||
|
||||
|
||||
# Function to encode the image
|
||||
def encode_image(image_path):
|
||||
@ -25,7 +24,7 @@ response = client.responses.create(
|
||||
{
|
||||
"role": "user",
|
||||
"content": [
|
||||
{ "type": "input_text", "text": "what color is the image"},
|
||||
{"type": "input_text", "text": "what color is the image"},
|
||||
{
|
||||
"type": "input_image",
|
||||
"image_url": f"data:image/jpeg;base64,{base64_image}",
|
||||
@ -36,7 +35,6 @@ response = client.responses.create(
|
||||
)
|
||||
|
||||
|
||||
|
||||
print(response.output_text)
|
||||
print("response1 id===", response.id)
|
||||
print("sleeping for 20 seconds...")
|
||||
@ -45,9 +43,7 @@ print("making follow up request for existing id")
|
||||
response2 = client.responses.create(
|
||||
model="bedrock/us.anthropic.claude-haiku-4-5-20251001-v1:0",
|
||||
previous_response_id=response.id,
|
||||
input="ok, and what objects are in the image?"
|
||||
input="ok, and what objects are in the image?",
|
||||
)
|
||||
|
||||
print(response2.output_text)
|
||||
|
||||
|
||||
|
||||
@ -52,11 +52,11 @@ class RealtimeClient:
|
||||
async def connect(self):
|
||||
"""Connect to LiteLLM proxy realtime endpoint."""
|
||||
print(f"Connecting to {self.url}...")
|
||||
|
||||
|
||||
headers = {}
|
||||
if self.api_key:
|
||||
headers["Authorization"] = f"Bearer {self.api_key}"
|
||||
|
||||
|
||||
self.ws = await websockets.connect(
|
||||
self.url,
|
||||
additional_headers=headers,
|
||||
@ -175,7 +175,9 @@ class RealtimeClient:
|
||||
|
||||
try:
|
||||
while self.is_active:
|
||||
audio_data = self.input_stream.read(CHUNK_SIZE, exception_on_overflow=False)
|
||||
audio_data = self.input_stream.read(
|
||||
CHUNK_SIZE, exception_on_overflow=False
|
||||
)
|
||||
await self.send_audio_chunk(audio_data)
|
||||
await asyncio.sleep(0.01) # Small delay to prevent overwhelming
|
||||
except Exception as e:
|
||||
@ -270,6 +272,7 @@ async def main():
|
||||
except Exception as e:
|
||||
print(f"\n❌ Error: {e}")
|
||||
import traceback
|
||||
|
||||
traceback.print_exc()
|
||||
finally:
|
||||
await client.close()
|
||||
@ -281,7 +284,7 @@ if __name__ == "__main__":
|
||||
print("2. Bedrock is configured in proxy_server_config.yaml")
|
||||
print("3. AWS credentials are set")
|
||||
print()
|
||||
|
||||
|
||||
try:
|
||||
asyncio.run(main())
|
||||
except KeyboardInterrupt:
|
||||
|
||||
@ -21,49 +21,45 @@ from typing import Optional
|
||||
|
||||
class VeoVideoGenerator:
|
||||
"""Complete Veo video generation client using LiteLLM proxy."""
|
||||
|
||||
def __init__(self, base_url: str = "http://localhost:4000/gemini/v1beta",
|
||||
api_key: str = "sk-1234"):
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str = "http://localhost:4000/gemini/v1beta",
|
||||
api_key: str = "sk-1234",
|
||||
):
|
||||
"""
|
||||
Initialize the Veo video generator.
|
||||
|
||||
|
||||
Args:
|
||||
base_url: Base URL for the LiteLLM proxy with Gemini pass-through
|
||||
api_key: API key for LiteLLM proxy authentication
|
||||
"""
|
||||
self.base_url = base_url
|
||||
self.api_key = api_key
|
||||
self.headers = {
|
||||
"x-goog-api-key": api_key,
|
||||
"Content-Type": "application/json"
|
||||
}
|
||||
|
||||
self.headers = {"x-goog-api-key": api_key, "Content-Type": "application/json"}
|
||||
|
||||
def generate_video(self, prompt: str) -> Optional[str]:
|
||||
"""
|
||||
Initiate video generation with Veo.
|
||||
|
||||
|
||||
Args:
|
||||
prompt: Text description of the video to generate
|
||||
|
||||
|
||||
Returns:
|
||||
Operation name if successful, None otherwise
|
||||
"""
|
||||
print(f"🎬 Generating video with prompt: '{prompt}'")
|
||||
|
||||
|
||||
url = f"{self.base_url}/models/veo-3.0-generate-preview:predictLongRunning"
|
||||
payload = {
|
||||
"instances": [{
|
||||
"prompt": prompt
|
||||
}]
|
||||
}
|
||||
|
||||
payload = {"instances": [{"prompt": prompt}]}
|
||||
|
||||
try:
|
||||
response = requests.post(url, headers=self.headers, json=payload)
|
||||
response.raise_for_status()
|
||||
|
||||
|
||||
data = response.json()
|
||||
operation_name = data.get("name")
|
||||
|
||||
|
||||
if operation_name:
|
||||
print(f"✅ Video generation started: {operation_name}")
|
||||
return operation_name
|
||||
@ -71,58 +67,64 @@ class VeoVideoGenerator:
|
||||
print("❌ No operation name returned")
|
||||
print(f"Response: {json.dumps(data, indent=2)}")
|
||||
return None
|
||||
|
||||
|
||||
except requests.RequestException as e:
|
||||
print(f"❌ Failed to start video generation: {e}")
|
||||
if hasattr(e, 'response') and e.response is not None:
|
||||
if hasattr(e, "response") and e.response is not None:
|
||||
try:
|
||||
error_data = e.response.json()
|
||||
print(f"Error details: {json.dumps(error_data, indent=2)}")
|
||||
except:
|
||||
print(f"Error response: {e.response.text}")
|
||||
return None
|
||||
|
||||
def wait_for_completion(self, operation_name: str, max_wait_time: int = 600) -> Optional[str]:
|
||||
|
||||
def wait_for_completion(
|
||||
self, operation_name: str, max_wait_time: int = 600
|
||||
) -> Optional[str]:
|
||||
"""
|
||||
Poll operation status until video generation is complete.
|
||||
|
||||
|
||||
Args:
|
||||
operation_name: Name of the operation to monitor
|
||||
max_wait_time: Maximum time to wait in seconds (default: 10 minutes)
|
||||
|
||||
|
||||
Returns:
|
||||
Video URI if successful, None otherwise
|
||||
"""
|
||||
print("⏳ Waiting for video generation to complete...")
|
||||
|
||||
|
||||
operation_url = f"{self.base_url}/{operation_name}"
|
||||
start_time = time.time()
|
||||
poll_interval = 10 # Start with 10 seconds
|
||||
|
||||
|
||||
while time.time() - start_time < max_wait_time:
|
||||
try:
|
||||
print(f"🔍 Polling status... ({int(time.time() - start_time)}s elapsed)")
|
||||
|
||||
print(
|
||||
f"🔍 Polling status... ({int(time.time() - start_time)}s elapsed)"
|
||||
)
|
||||
|
||||
response = requests.get(operation_url, headers=self.headers)
|
||||
response.raise_for_status()
|
||||
|
||||
|
||||
data = response.json()
|
||||
|
||||
|
||||
# Check for errors
|
||||
if "error" in data:
|
||||
print("❌ Error in video generation:")
|
||||
print(json.dumps(data["error"], indent=2))
|
||||
return None
|
||||
|
||||
|
||||
# Check if operation is complete
|
||||
is_done = data.get("done", False)
|
||||
|
||||
|
||||
if is_done:
|
||||
print("🎉 Video generation complete!")
|
||||
|
||||
|
||||
try:
|
||||
# Extract video URI from nested response
|
||||
video_uri = data["response"]["generateVideoResponse"]["generatedSamples"][0]["video"]["uri"]
|
||||
video_uri = data["response"]["generateVideoResponse"][
|
||||
"generatedSamples"
|
||||
][0]["video"]["uri"]
|
||||
print(f"📹 Video URI: {video_uri}")
|
||||
return video_uri
|
||||
except KeyError as e:
|
||||
@ -130,64 +132,68 @@ class VeoVideoGenerator:
|
||||
print("Full response:")
|
||||
print(json.dumps(data, indent=2))
|
||||
return None
|
||||
|
||||
|
||||
# Wait before next poll, with exponential backoff
|
||||
time.sleep(poll_interval)
|
||||
poll_interval = min(poll_interval * 1.2, 30) # Cap at 30 seconds
|
||||
|
||||
|
||||
except requests.RequestException as e:
|
||||
print(f"❌ Error polling operation status: {e}")
|
||||
time.sleep(poll_interval)
|
||||
|
||||
|
||||
print(f"⏰ Timeout after {max_wait_time} seconds")
|
||||
return None
|
||||
|
||||
def download_video(self, video_uri: str, output_filename: str = "generated_video.mp4") -> bool:
|
||||
|
||||
def download_video(
|
||||
self, video_uri: str, output_filename: str = "generated_video.mp4"
|
||||
) -> bool:
|
||||
"""
|
||||
Download the generated video file.
|
||||
|
||||
|
||||
Args:
|
||||
video_uri: URI of the video to download (from Google's response)
|
||||
output_filename: Local filename to save the video
|
||||
|
||||
|
||||
Returns:
|
||||
True if download successful, False otherwise
|
||||
"""
|
||||
print(f"⬇️ Downloading video...")
|
||||
print(f"Original URI: {video_uri}")
|
||||
|
||||
|
||||
# Convert Google URI to LiteLLM proxy URI
|
||||
# Example: files/abc123 -> /gemini/v1beta/files/abc123:download?alt=media
|
||||
if video_uri.startswith("files/"):
|
||||
download_path = f"{video_uri}:download?alt=media"
|
||||
else:
|
||||
download_path = video_uri
|
||||
|
||||
|
||||
litellm_download_url = f"{self.base_url}/{download_path}"
|
||||
print(f"Download URL: {litellm_download_url}")
|
||||
|
||||
|
||||
try:
|
||||
# Download with streaming and redirect handling
|
||||
response = requests.get(
|
||||
litellm_download_url,
|
||||
headers=self.headers,
|
||||
litellm_download_url,
|
||||
headers=self.headers,
|
||||
stream=True,
|
||||
allow_redirects=True # Handle redirects automatically
|
||||
allow_redirects=True, # Handle redirects automatically
|
||||
)
|
||||
response.raise_for_status()
|
||||
|
||||
|
||||
# Save video file
|
||||
with open(output_filename, 'wb') as f:
|
||||
with open(output_filename, "wb") as f:
|
||||
downloaded_size = 0
|
||||
for chunk in response.iter_content(chunk_size=8192):
|
||||
if chunk:
|
||||
f.write(chunk)
|
||||
downloaded_size += len(chunk)
|
||||
|
||||
|
||||
# Progress indicator for large files
|
||||
if downloaded_size % (1024 * 1024) == 0: # Every MB
|
||||
print(f"📦 Downloaded {downloaded_size / (1024*1024):.1f} MB...")
|
||||
|
||||
print(
|
||||
f"📦 Downloaded {downloaded_size / (1024*1024):.1f} MB..."
|
||||
)
|
||||
|
||||
# Verify file was created and has content
|
||||
if os.path.exists(output_filename):
|
||||
file_size = os.path.getsize(output_filename)
|
||||
@ -203,48 +209,52 @@ class VeoVideoGenerator:
|
||||
else:
|
||||
print("❌ File was not created")
|
||||
return False
|
||||
|
||||
|
||||
except requests.RequestException as e:
|
||||
print(f"❌ Download failed: {e}")
|
||||
if hasattr(e, 'response') and e.response is not None:
|
||||
if hasattr(e, "response") and e.response is not None:
|
||||
print(f"Status code: {e.response.status_code}")
|
||||
print(f"Response headers: {dict(e.response.headers)}")
|
||||
return False
|
||||
|
||||
|
||||
def generate_and_download(self, prompt: str, output_filename: str = None) -> bool:
|
||||
"""
|
||||
Complete workflow: generate video and download it.
|
||||
|
||||
|
||||
Args:
|
||||
prompt: Text description for video generation
|
||||
output_filename: Output filename (auto-generated if None)
|
||||
|
||||
|
||||
Returns:
|
||||
True if successful, False otherwise
|
||||
"""
|
||||
# Auto-generate filename if not provided
|
||||
if output_filename is None:
|
||||
timestamp = int(time.time())
|
||||
safe_prompt = "".join(c for c in prompt[:30] if c.isalnum() or c in (' ', '-', '_')).rstrip()
|
||||
output_filename = f"veo_video_{safe_prompt.replace(' ', '_')}_{timestamp}.mp4"
|
||||
|
||||
safe_prompt = "".join(
|
||||
c for c in prompt[:30] if c.isalnum() or c in (" ", "-", "_")
|
||||
).rstrip()
|
||||
output_filename = (
|
||||
f"veo_video_{safe_prompt.replace(' ', '_')}_{timestamp}.mp4"
|
||||
)
|
||||
|
||||
print("=" * 60)
|
||||
print("🎬 VEO VIDEO GENERATION WORKFLOW")
|
||||
print("=" * 60)
|
||||
|
||||
|
||||
# Step 1: Generate video
|
||||
operation_name = self.generate_video(prompt)
|
||||
if not operation_name:
|
||||
return False
|
||||
|
||||
|
||||
# Step 2: Wait for completion
|
||||
video_uri = self.wait_for_completion(operation_name)
|
||||
if not video_uri:
|
||||
return False
|
||||
|
||||
|
||||
# Step 3: Download video
|
||||
success = self.download_video(video_uri, output_filename)
|
||||
|
||||
|
||||
if success:
|
||||
print("=" * 60)
|
||||
print("🎉 SUCCESS! Video generation complete!")
|
||||
@ -254,51 +264,51 @@ class VeoVideoGenerator:
|
||||
print("=" * 60)
|
||||
print("❌ FAILED! Video generation or download failed")
|
||||
print("=" * 60)
|
||||
|
||||
|
||||
return success
|
||||
|
||||
|
||||
def main():
|
||||
"""
|
||||
Example usage of the VeoVideoGenerator.
|
||||
|
||||
|
||||
Configure these environment variables:
|
||||
- LITELLM_BASE_URL: Your LiteLLM proxy URL (default: http://localhost:4000/gemini/v1beta)
|
||||
- LITELLM_API_KEY: Your LiteLLM API key (default: sk-1234)
|
||||
"""
|
||||
|
||||
|
||||
# Configuration from environment or defaults
|
||||
base_url = os.getenv("LITELLM_BASE_URL", "http://localhost:4000/gemini/v1beta")
|
||||
api_key = os.getenv("LITELLM_API_KEY", "sk-1234")
|
||||
|
||||
|
||||
print("🚀 Starting Veo Video Generation Example")
|
||||
print(f"📡 Using LiteLLM proxy at: {base_url}")
|
||||
|
||||
|
||||
# Initialize generator
|
||||
generator = VeoVideoGenerator(base_url=base_url, api_key=api_key)
|
||||
|
||||
|
||||
# Example prompts - try different ones!
|
||||
example_prompts = [
|
||||
"A cat playing with a ball of yarn in a sunny garden",
|
||||
"Ocean waves crashing against rocky cliffs at sunset",
|
||||
"A bustling city street with people walking and cars passing by",
|
||||
"A peaceful forest with sunlight filtering through the trees"
|
||||
"A peaceful forest with sunlight filtering through the trees",
|
||||
]
|
||||
|
||||
|
||||
# Use first example or get from user
|
||||
prompt = example_prompts[0]
|
||||
print(f"🎬 Using prompt: '{prompt}'")
|
||||
|
||||
|
||||
# Generate and download video
|
||||
success = generator.generate_and_download(prompt)
|
||||
|
||||
|
||||
if success:
|
||||
print("\n✅ Example completed successfully!")
|
||||
print("💡 Try modifying the prompt in the script for different videos!")
|
||||
else:
|
||||
print("\n❌ Example failed!")
|
||||
print("🔧 Check your LiteLLM proxy configuration and Google AI Studio API key")
|
||||
|
||||
|
||||
# Troubleshooting tips
|
||||
print("\n🔍 Troubleshooting:")
|
||||
print("1. Ensure LiteLLM proxy is running with Google AI Studio pass-through")
|
||||
|
||||
@ -333,6 +333,67 @@ curl 'http://0.0.0.0:4000/key/generate' \
|
||||
}'
|
||||
```
|
||||
|
||||
#### **Set multiple budget windows on a key**
|
||||
|
||||
Apply multiple concurrent budget limits at different time scales on the same key — for example, cap a key at **$10/day** AND **$100/month**.
|
||||
|
||||
**When is this useful?**
|
||||
|
||||
A single `budget_duration` window can't prevent a bad day from burning your entire month. Multiple budget windows let you:
|
||||
|
||||
- Block a runaway usage spike within the day while still allowing normal monthly spend.
|
||||
- Give Claude Code rollouts a daily guardrail (`24h`) and a monthly ceiling (`30d`) so a single heavy session doesn't exhaust the whole month.
|
||||
- Layer fine-grained hourly limits for bursty workloads on top of a weekly cap.
|
||||
|
||||
:::info
|
||||
|
||||
See [User Budget docs](https://docs.litellm.ai/docs/proxy/users) for more on how budgets work across keys, teams, and users.
|
||||
|
||||
:::
|
||||
|
||||
**Via API**
|
||||
|
||||
Pass `budget_limits` as a list of `{budget_duration, max_budget}` objects:
|
||||
|
||||
```bash
|
||||
curl 'http://0.0.0.0:4000/key/generate' \
|
||||
--header 'Authorization: Bearer <your-master-key>' \
|
||||
--header 'Content-Type: application/json' \
|
||||
--data-raw '{
|
||||
"budget_limits": [
|
||||
{"budget_duration": "24h", "max_budget": 10},
|
||||
{"budget_duration": "30d", "max_budget": 100}
|
||||
]
|
||||
}'
|
||||
```
|
||||
|
||||
Each window is tracked independently and resets on its own schedule:
|
||||
|
||||
| `budget_duration` | Resets |
|
||||
|---|---|
|
||||
| `1h` | Every hour |
|
||||
| `24h` | Daily at midnight UTC |
|
||||
| `7d` | Every Sunday at midnight UTC |
|
||||
| `30d` | 1st of every month at midnight UTC |
|
||||
|
||||
**Via Dashboard**
|
||||
|
||||
Open **Virtual Keys → Create Key → Optional Settings → Budget Windows**.
|
||||
|
||||
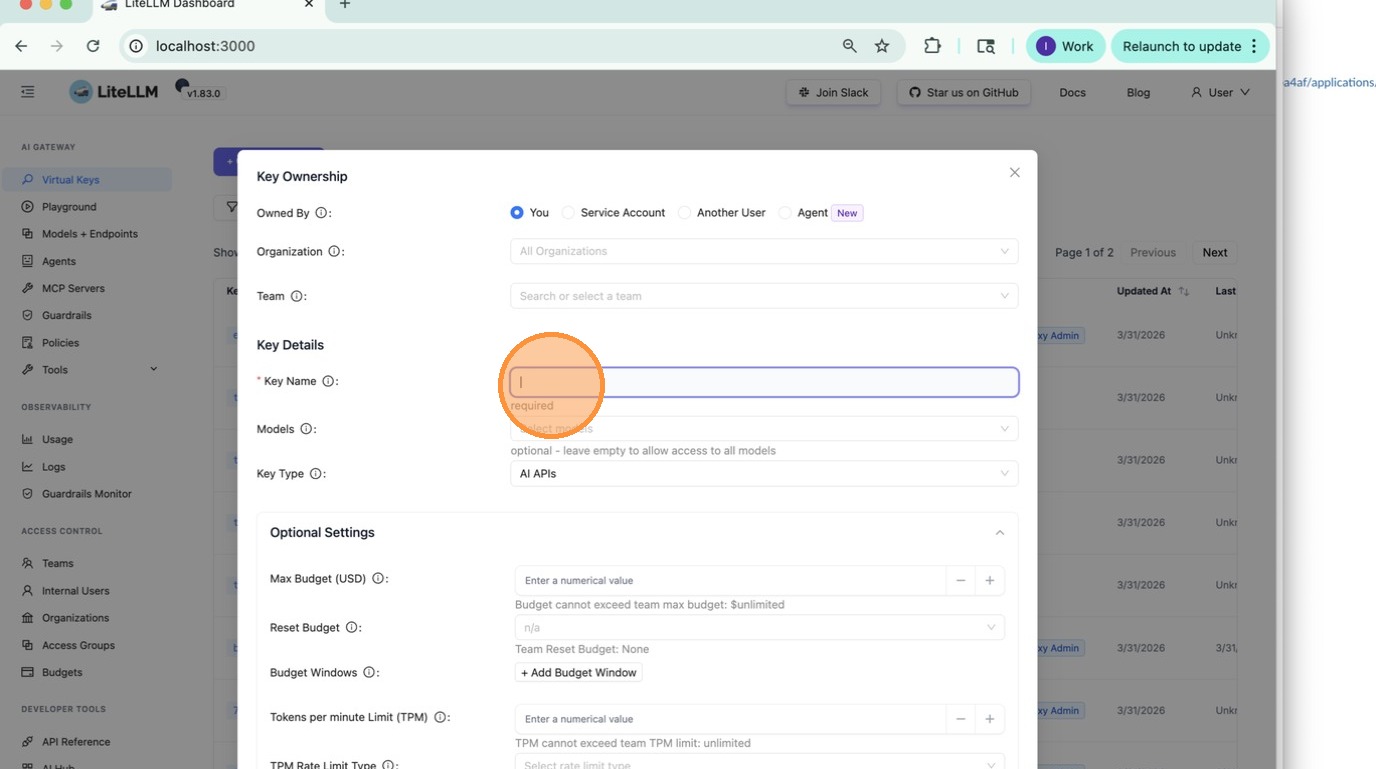
|
||||
|
||||
Click **+ Add Budget Window** to add a row, choose the period from the dropdown, and enter the spend cap.
|
||||
|
||||
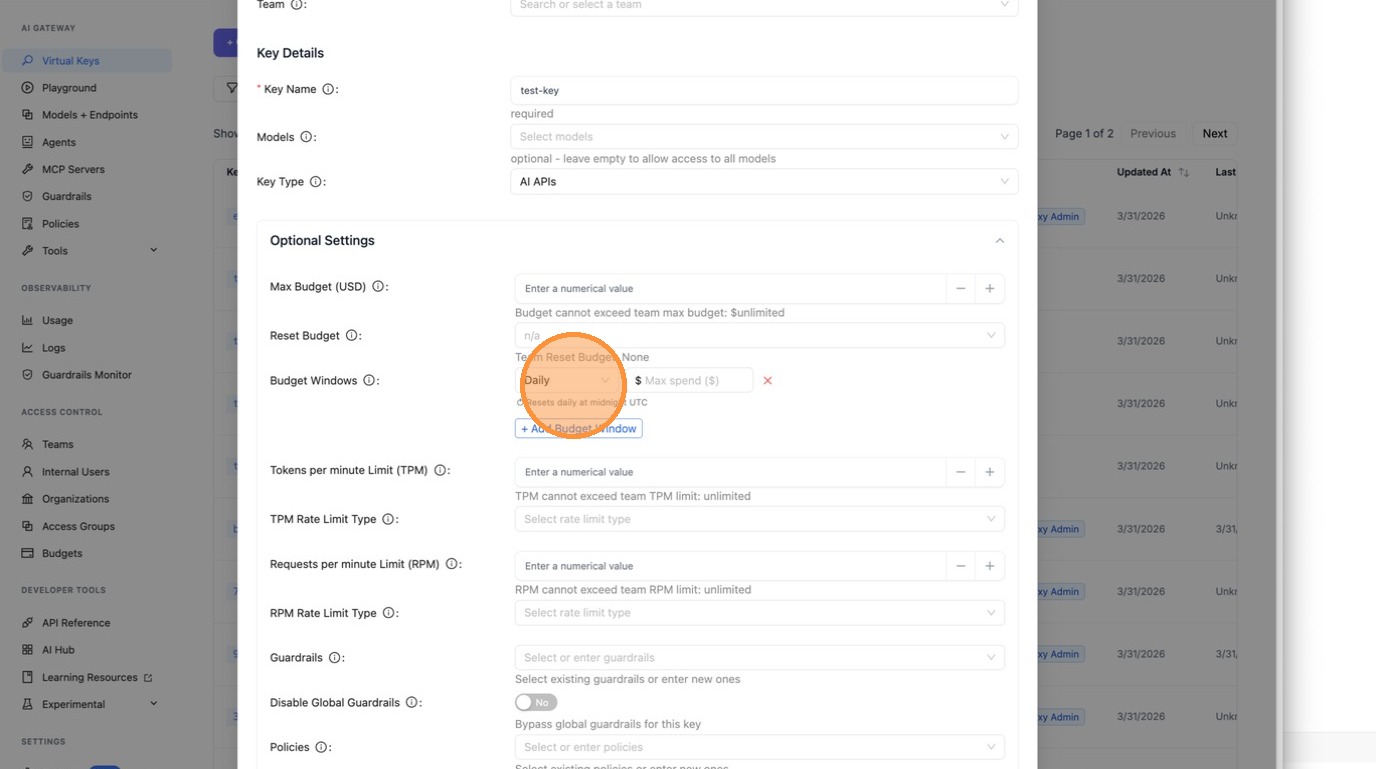
|
||||
|
||||
Add a second row for a different time period (e.g. monthly $100 on top of a daily $10).
|
||||
|
||||
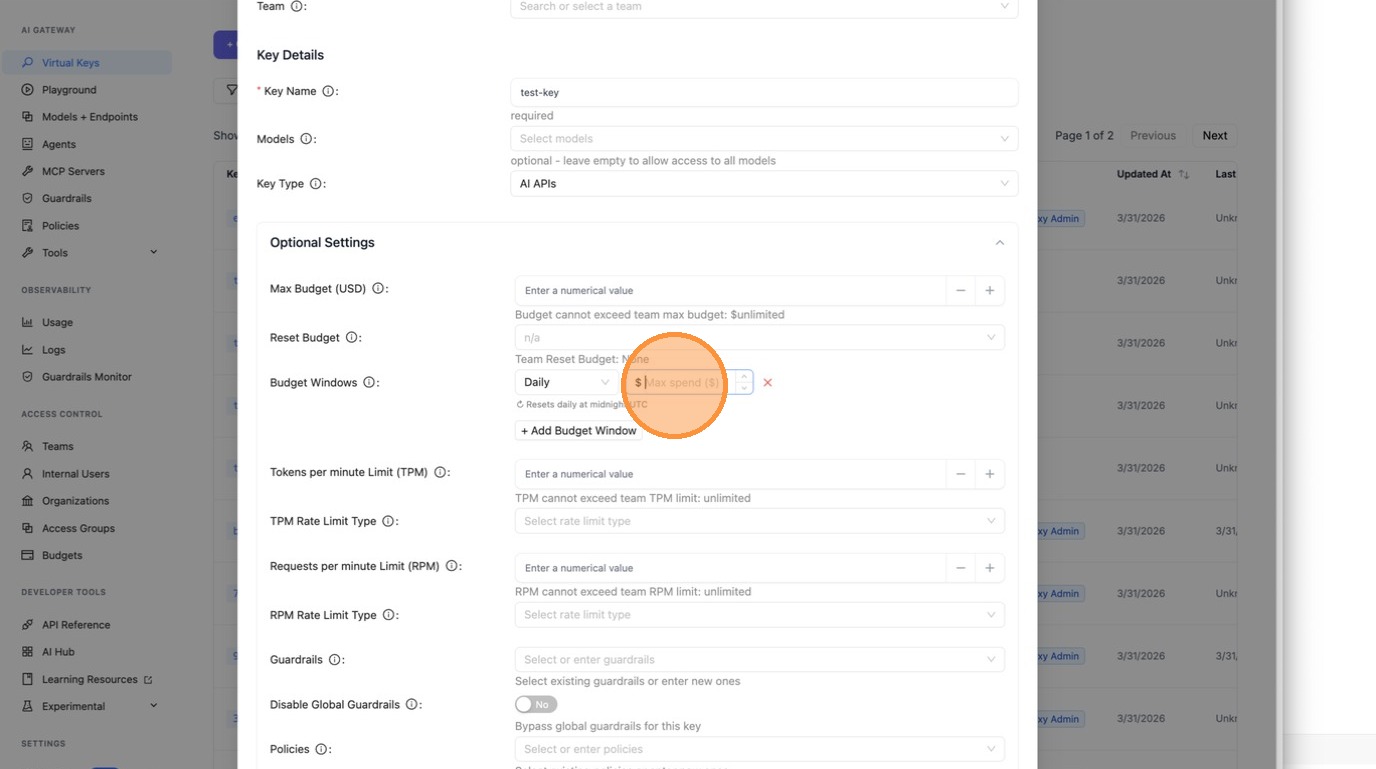
|
||||
|
||||
Each window shows the reset schedule below the input so it's always clear when spend resets.
|
||||
|
||||
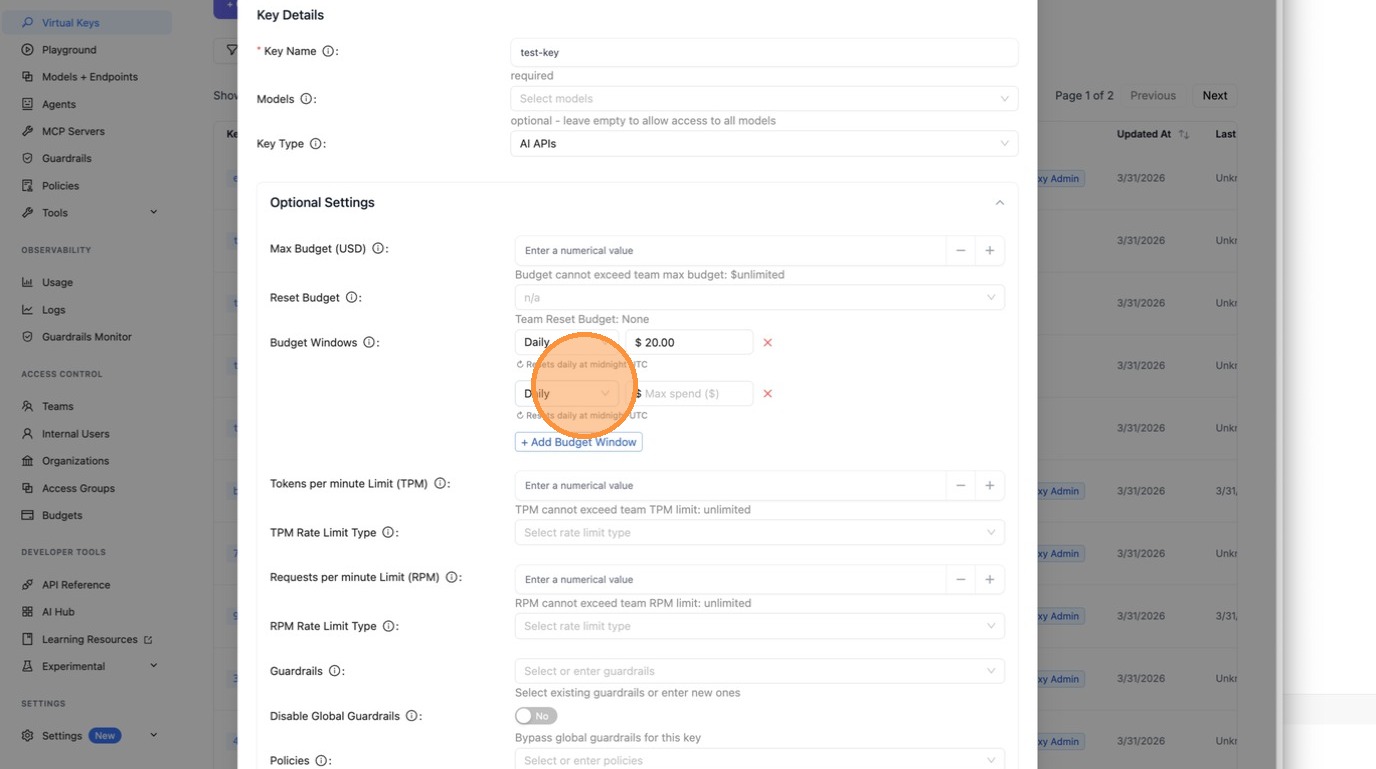
|
||||
|
||||
|
||||
### ✨ Virtual Key (Model Specific)
|
||||
|
||||
|
||||
111
docs/my-website/docs/skills_gateway.md
Normal file
111
docs/my-website/docs/skills_gateway.md
Normal file
@ -0,0 +1,111 @@
|
||||
# Skills Gateway
|
||||
|
||||
<iframe width="840" height="500" src="https://www.loom.com/embed/cb74eb79df3e4c2b83a6efae54a589f9" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>
|
||||
|
||||
LiteLLM acts as a **Skills Registry** — a central place to register, manage, and discover Claude Code skills across your organization. Teams can publish skills once and have agents and developers find them through a single hub.
|
||||
|
||||
## How it works
|
||||
|
||||
```mermaid
|
||||
graph TD
|
||||
Dev["👨💻 Developer<br/>registers a skill<br/>(GitHub URL or subdir)"] -->|POST /claude-code/plugins| Proxy["LiteLLM Proxy<br/>(Skills Registry)"]
|
||||
|
||||
Admin["🔑 Admin<br/>publishes skill<br/>(marks as public)"] -->|enable via UI or API| Proxy
|
||||
|
||||
Proxy -->|GET /public/skill_hub| SkillHub["🗂️ Skill Hub<br/>(AI Hub → Skill Hub tab)"]
|
||||
Proxy -->|GET /claude-code/marketplace.json| Marketplace["📦 Claude Code<br/>Marketplace endpoint"]
|
||||
|
||||
SkillHub --> Human["🧑 Human<br/>browses & discovers skills<br/>in AI Hub UI"]
|
||||
Marketplace --> Agent["🤖 Agent / Claude Code<br/>installs skill with<br/>/plugin marketplace add <name>"]
|
||||
|
||||
style Proxy fill:#1a73e8,color:#fff
|
||||
style SkillHub fill:#e8f0fe,color:#1a73e8
|
||||
style Marketplace fill:#e8f0fe,color:#1a73e8
|
||||
```
|
||||
|
||||
## Quick start
|
||||
|
||||
### 1. Register a skill
|
||||
|
||||
Paste any GitHub URL into the Skills UI — LiteLLM auto-detects the source type and skill name.
|
||||
|
||||
```bash
|
||||
curl -X POST https://your-proxy/claude-code/plugins \
|
||||
-H "Authorization: Bearer $LITELLM_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"name": "grill-me",
|
||||
"source": {
|
||||
"source": "git-subdir",
|
||||
"url": "https://github.com/mattpocock/skills",
|
||||
"path": "grill-me"
|
||||
},
|
||||
"description": "Interview skill for relentless questioning",
|
||||
"domain": "Productivity",
|
||||
"namespace": "interviews"
|
||||
}'
|
||||
```
|
||||
|
||||
Skills nested in subdirectories (e.g. `github.com/org/repo/tree/main/skill-name`) are supported — LiteLLM parses the URL automatically in the UI.
|
||||
|
||||
### 2. Publish to hub
|
||||
|
||||
In the Admin UI: **AI Hub → Skill Hub → Select Skills to Make Public**.
|
||||
|
||||
Or via API:
|
||||
|
||||
```bash
|
||||
curl -X POST https://your-proxy/claude-code/plugins/grill-me/enable \
|
||||
-H "Authorization: Bearer $LITELLM_KEY"
|
||||
```
|
||||
|
||||
### 3. Browse the hub
|
||||
|
||||
Public skills appear at:
|
||||
- **Admin UI**: AI Hub → Skill Hub tab
|
||||
- **Public page**: `/ui/model_hub` → Skill Hub tab (no login required)
|
||||
- **API**: `GET /public/skill_hub`
|
||||
|
||||
### 4. Install in Claude Code
|
||||
|
||||
Point Claude Code at your proxy marketplace once:
|
||||
|
||||
```json title="~/.claude/settings.json"
|
||||
{
|
||||
"extraKnownMarketplaces": {
|
||||
"my-org": {
|
||||
"source": "url",
|
||||
"url": "https://your-proxy/claude-code/marketplace.json"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Then install any skill:
|
||||
|
||||
```
|
||||
/plugin marketplace add grill-me
|
||||
```
|
||||
|
||||
## Skill fields
|
||||
|
||||
| Field | Description |
|
||||
|-------|-------------|
|
||||
| `name` | Unique skill identifier (used in `/plugin marketplace add`) |
|
||||
| `source` | Git source — `github`, `url`, or `git-subdir` |
|
||||
| `description` | Short description shown in the hub |
|
||||
| `domain` | Category for grouping (e.g. `Engineering`, `Productivity`) |
|
||||
| `namespace` | Subcategory within a domain (e.g. `quality`, `meetings`) |
|
||||
| `keywords` | Tags for search and filtering |
|
||||
| `version` | Semver string |
|
||||
|
||||
## API reference
|
||||
|
||||
| Endpoint | Auth | Description |
|
||||
|----------|------|-------------|
|
||||
| `POST /claude-code/plugins` | Required | Register a skill |
|
||||
| `GET /claude-code/plugins` | Required | List all skills (admin) |
|
||||
| `POST /claude-code/plugins/{name}/enable` | Required | Publish a skill |
|
||||
| `POST /claude-code/plugins/{name}/disable` | Required | Unpublish a skill |
|
||||
| `GET /public/skill_hub` | None | List public skills |
|
||||
| `GET /claude-code/marketplace.json` | None | Claude Code marketplace manifest |
|
||||
@ -339,6 +339,13 @@ const sidebars = {
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
type: "category",
|
||||
label: "Skills Gateway",
|
||||
items: [
|
||||
"skills_gateway",
|
||||
],
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
|
||||
@ -23,7 +23,8 @@ class JsonFormatter(logging.Formatter):
|
||||
def _is_json_enabled():
|
||||
try:
|
||||
import litellm
|
||||
return getattr(litellm, 'json_logs', False)
|
||||
|
||||
return getattr(litellm, "json_logs", False)
|
||||
except (ImportError, AttributeError):
|
||||
return os.getenv("JSON_LOGS", "false").lower() == "true"
|
||||
|
||||
@ -35,6 +36,8 @@ if not logger.handlers:
|
||||
if _is_json_enabled():
|
||||
handler.setFormatter(JsonFormatter())
|
||||
else:
|
||||
handler.setFormatter(logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s"))
|
||||
handler.setFormatter(
|
||||
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
|
||||
)
|
||||
logger.addHandler(handler)
|
||||
logger.setLevel(logging.INFO)
|
||||
|
||||
@ -0,0 +1,5 @@
|
||||
-- AlterTable: add budget_limits column to LiteLLM_VerificationToken
|
||||
ALTER TABLE "LiteLLM_VerificationToken" ADD COLUMN IF NOT EXISTS "budget_limits" JSONB;
|
||||
|
||||
-- AlterTable: add budget_limits column to LiteLLM_TeamTable
|
||||
ALTER TABLE "LiteLLM_TeamTable" ADD COLUMN IF NOT EXISTS "budget_limits" JSONB;
|
||||
@ -0,0 +1,9 @@
|
||||
-- Add per-member model scope to LiteLLM_BudgetTable
|
||||
-- allowed_models: empty array = inherit team models; non-empty = enforce member-level restriction
|
||||
ALTER TABLE "LiteLLM_BudgetTable"
|
||||
ADD COLUMN IF NOT EXISTS "allowed_models" TEXT[] DEFAULT ARRAY[]::TEXT[];
|
||||
|
||||
-- Add default_team_member_models to LiteLLM_TeamTable
|
||||
-- Seeds allowed_models for newly added team members; empty = no per-member restriction
|
||||
ALTER TABLE "LiteLLM_TeamTable"
|
||||
ADD COLUMN IF NOT EXISTS "default_team_member_models" TEXT[] DEFAULT ARRAY[]::TEXT[];
|
||||
@ -17,8 +17,9 @@ model LiteLLM_BudgetTable {
|
||||
tpm_limit BigInt?
|
||||
rpm_limit BigInt?
|
||||
model_max_budget Json?
|
||||
budget_duration String?
|
||||
budget_duration String?
|
||||
budget_reset_at DateTime?
|
||||
allowed_models String[] @default([]) // per-member model scope; empty = inherit team models
|
||||
created_at DateTime @default(now()) @map("created_at")
|
||||
created_by String
|
||||
updated_at DateTime @default(now()) @updatedAt @map("updated_at")
|
||||
@ -140,6 +141,8 @@ model LiteLLM_TeamTable {
|
||||
team_member_permissions String[] @default([])
|
||||
access_group_ids String[] @default([])
|
||||
policies String[] @default([])
|
||||
default_team_member_models String[] @default([]) // default allowed_models for newly added team members; empty = no per-member restriction
|
||||
budget_limits Json? // per-model budget limits for the team
|
||||
model_id Int? @unique // id for LiteLLM_ModelTable -> stores team-level model aliases
|
||||
allow_team_guardrail_config Boolean @default(false) // if true, team admin can configure guardrails for this team
|
||||
litellm_organization_table LiteLLM_OrganizationTable? @relation(fields: [organization_id], references: [organization_id])
|
||||
@ -401,6 +404,7 @@ model LiteLLM_VerificationToken {
|
||||
rotation_interval String? // How often to rotate (e.g., "30d", "90d")
|
||||
last_rotation_at DateTime? // When this key was last rotated
|
||||
key_rotation_at DateTime? // When this key should next be rotated
|
||||
budget_limits Json? // per-model budget limits for the key
|
||||
litellm_budget_table LiteLLM_BudgetTable? @relation(fields: [budget_id], references: [budget_id])
|
||||
litellm_organization_table LiteLLM_OrganizationTable? @relation(fields: [organization_id], references: [organization_id])
|
||||
litellm_project_table LiteLLM_ProjectTable? @relation(fields: [project_id], references: [project_id])
|
||||
|
||||
@ -4,8 +4,8 @@ import random
|
||||
import re
|
||||
import shutil
|
||||
import subprocess
|
||||
import tempfile
|
||||
import time
|
||||
from datetime import datetime
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
@ -256,21 +256,11 @@ class ProxyExtrasDBManager:
|
||||
if not database_url:
|
||||
logger.error("DATABASE_URL not set")
|
||||
return
|
||||
# Prefer DIRECT_URL for schema introspection — pooler URLs (e.g. neon -pooler)
|
||||
# do not support the extended query protocol required by prisma migrate diff.
|
||||
diff_url = os.getenv("DIRECT_URL") or database_url
|
||||
|
||||
diff_dir = (
|
||||
Path(migrations_dir)
|
||||
/ "migrations"
|
||||
/ f"{datetime.now().strftime('%Y%m%d%H%M%S')}_baseline_diff"
|
||||
)
|
||||
try:
|
||||
diff_dir.mkdir(parents=True, exist_ok=True)
|
||||
except Exception as e:
|
||||
if "Permission denied" in str(e):
|
||||
logger.warning(
|
||||
f"Permission denied - {e}\nunable to baseline db. Set LITELLM_MIGRATION_DIR environment variable to a writable directory to enable migrations."
|
||||
)
|
||||
return
|
||||
raise e
|
||||
diff_dir = Path(tempfile.mkdtemp(prefix="litellm_migration_diff_"))
|
||||
diff_sql_path = diff_dir / "migration.sql"
|
||||
|
||||
# 1. Generate migration SQL for the diff between DB and schema
|
||||
@ -283,7 +273,7 @@ class ProxyExtrasDBManager:
|
||||
"migrate",
|
||||
"diff",
|
||||
"--from-url",
|
||||
database_url,
|
||||
diff_url,
|
||||
"--to-schema-datamodel",
|
||||
schema_path,
|
||||
"--script",
|
||||
@ -300,7 +290,40 @@ class ProxyExtrasDBManager:
|
||||
|
||||
# check if the migration was created
|
||||
if not diff_sql_path.exists():
|
||||
logger.warning("Migration diff was not created")
|
||||
logger.warning(
|
||||
"Migration diff was not created (prisma migrate diff failed — "
|
||||
"likely a pooler URL). Falling back to direct SQL execution of "
|
||||
"each migration file."
|
||||
)
|
||||
# Fall back: run each migration SQL file directly via prisma db execute.
|
||||
# This works with pooler URLs (no schema introspection needed) and is
|
||||
# safe to re-run because migrations use IF NOT EXISTS / IF EXISTS guards.
|
||||
migration_files = sorted(Path(migrations_dir).glob("*/migration.sql"))
|
||||
for mig_file in migration_files:
|
||||
try:
|
||||
subprocess.run(
|
||||
[
|
||||
_get_prisma_command(),
|
||||
"db",
|
||||
"execute",
|
||||
"--file",
|
||||
str(mig_file),
|
||||
"--schema",
|
||||
schema_path,
|
||||
],
|
||||
timeout=60,
|
||||
check=True,
|
||||
capture_output=True,
|
||||
text=True,
|
||||
env=_get_prisma_env(),
|
||||
)
|
||||
logger.info(f"Applied migration: {mig_file.parent.name}")
|
||||
except subprocess.CalledProcessError as e:
|
||||
logger.warning(
|
||||
f"Failed to apply migration {mig_file.parent.name}: {e.stderr}"
|
||||
)
|
||||
except subprocess.TimeoutExpired:
|
||||
logger.warning(f"Migration {mig_file.parent.name} timed out.")
|
||||
return
|
||||
logger.info(f"Migration diff created at {diff_sql_path}")
|
||||
|
||||
@ -395,6 +418,14 @@ class ProxyExtrasDBManager:
|
||||
|
||||
logger.info("prisma migrate deploy completed")
|
||||
|
||||
# Skip sanity check when deploy reports no pending migrations —
|
||||
# DB already matches schema, no drift to correct.
|
||||
if "No pending migrations to apply" in result.stdout:
|
||||
logger.info(
|
||||
"No pending migrations — skipping post-migration sanity check"
|
||||
)
|
||||
return True
|
||||
|
||||
# Run sanity check to ensure DB matches schema
|
||||
logger.info("Running post-migration sanity check...")
|
||||
ProxyExtrasDBManager._resolve_all_migrations(
|
||||
@ -419,7 +450,10 @@ class ProxyExtrasDBManager:
|
||||
ProxyExtrasDBManager._roll_back_migration(
|
||||
failed_migration
|
||||
)
|
||||
except (subprocess.CalledProcessError, subprocess.TimeoutExpired) as rollback_err:
|
||||
except (
|
||||
subprocess.CalledProcessError,
|
||||
subprocess.TimeoutExpired,
|
||||
) as rollback_err:
|
||||
logger.warning(
|
||||
f"Failed to roll back migration {failed_migration}: {rollback_err}. "
|
||||
f"It may already be in a rolled-back state."
|
||||
@ -431,10 +465,19 @@ class ProxyExtrasDBManager:
|
||||
logger.info(
|
||||
f"✅ Migration {failed_migration} resolved, retrying to apply remaining migrations"
|
||||
)
|
||||
except (subprocess.CalledProcessError, subprocess.TimeoutExpired) as resolve_err:
|
||||
except (
|
||||
subprocess.CalledProcessError,
|
||||
subprocess.TimeoutExpired,
|
||||
) as resolve_err:
|
||||
logger.warning(
|
||||
f"Failed to resolve migration {failed_migration}: {resolve_err}"
|
||||
)
|
||||
# Apply any schema drift not covered by the marked-as-applied migration
|
||||
ProxyExtrasDBManager._resolve_all_migrations(
|
||||
migrations_dir,
|
||||
schema_path,
|
||||
mark_all_applied=False,
|
||||
)
|
||||
else:
|
||||
logger.info(
|
||||
f"Found failed migration: {failed_migration}, marking as rolled back"
|
||||
@ -531,7 +574,10 @@ class ProxyExtrasDBManager:
|
||||
ProxyExtrasDBManager._roll_back_migration(
|
||||
migration_name
|
||||
)
|
||||
except (subprocess.CalledProcessError, subprocess.TimeoutExpired) as rollback_err:
|
||||
except (
|
||||
subprocess.CalledProcessError,
|
||||
subprocess.TimeoutExpired,
|
||||
) as rollback_err:
|
||||
logger.warning(
|
||||
f"Failed to roll back migration {migration_name}: {rollback_err}. "
|
||||
f"It may already be in a rolled-back state."
|
||||
@ -548,10 +594,19 @@ class ProxyExtrasDBManager:
|
||||
f"✅ Migration {migration_name} resolved, "
|
||||
f"retrying to apply remaining migrations"
|
||||
)
|
||||
except (subprocess.CalledProcessError, subprocess.TimeoutExpired) as resolve_err:
|
||||
except (
|
||||
subprocess.CalledProcessError,
|
||||
subprocess.TimeoutExpired,
|
||||
) as resolve_err:
|
||||
logger.warning(
|
||||
f"Failed to resolve migration {migration_name}: {resolve_err}"
|
||||
)
|
||||
# Apply any schema drift not covered by the marked-as-applied migration
|
||||
ProxyExtrasDBManager._resolve_all_migrations(
|
||||
migrations_dir,
|
||||
schema_path,
|
||||
mark_all_applied=False,
|
||||
)
|
||||
else:
|
||||
# Unknown P3018 error - log and re-raise for safety
|
||||
logger.warning(
|
||||
|
||||
@ -168,12 +168,12 @@ prometheus_latency_buckets: Optional[List[float]] = None
|
||||
require_auth_for_metrics_endpoint: Optional[bool] = False
|
||||
argilla_batch_size: Optional[int] = None
|
||||
datadog_use_v1: Optional[bool] = False # if you want to use v1 datadog logged payload.
|
||||
gcs_pub_sub_use_v1: Optional[
|
||||
bool
|
||||
] = False # if you want to use v1 gcs pubsub logged payload
|
||||
generic_api_use_v1: Optional[
|
||||
bool
|
||||
] = False # if you want to use v1 generic api logged payload
|
||||
gcs_pub_sub_use_v1: Optional[bool] = (
|
||||
False # if you want to use v1 gcs pubsub logged payload
|
||||
)
|
||||
generic_api_use_v1: Optional[bool] = (
|
||||
False # if you want to use v1 generic api logged payload
|
||||
)
|
||||
argilla_transformation_object: Optional[Dict[str, Any]] = None
|
||||
_async_input_callback: List[
|
||||
Union[str, Callable, "CustomLogger"]
|
||||
@ -193,26 +193,26 @@ _async_failure_callback: List[
|
||||
pre_call_rules: List[Callable] = []
|
||||
post_call_rules: List[Callable] = []
|
||||
turn_off_message_logging: Optional[bool] = False
|
||||
standard_logging_payload_excluded_fields: Optional[
|
||||
List[str]
|
||||
] = None # Fields to exclude from StandardLoggingPayload before callbacks receive it
|
||||
standard_logging_payload_excluded_fields: Optional[List[str]] = (
|
||||
None # Fields to exclude from StandardLoggingPayload before callbacks receive it
|
||||
)
|
||||
log_raw_request_response: bool = False
|
||||
redact_messages_in_exceptions: Optional[bool] = False
|
||||
redact_user_api_key_info: Optional[bool] = False
|
||||
filter_invalid_headers: Optional[bool] = False
|
||||
add_user_information_to_llm_headers: Optional[
|
||||
bool
|
||||
] = None # adds user_id, team_id, token hash (params from StandardLoggingMetadata) to request headers
|
||||
add_user_information_to_llm_headers: Optional[bool] = (
|
||||
None # adds user_id, team_id, token hash (params from StandardLoggingMetadata) to request headers
|
||||
)
|
||||
store_audit_logs = False # Enterprise feature, allow users to see audit logs
|
||||
skip_system_message_in_guardrail: bool = False
|
||||
### end of callbacks #############
|
||||
|
||||
email: Optional[
|
||||
str
|
||||
] = None # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
token: Optional[
|
||||
str
|
||||
] = None # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
email: Optional[str] = (
|
||||
None # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
)
|
||||
token: Optional[str] = (
|
||||
None # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
)
|
||||
telemetry = True
|
||||
max_tokens: int = DEFAULT_MAX_TOKENS # OpenAI Defaults
|
||||
drop_params = bool(os.getenv("LITELLM_DROP_PARAMS", False))
|
||||
@ -274,9 +274,9 @@ use_client: bool = False
|
||||
ssl_verify: Union[str, bool] = True
|
||||
ssl_security_level: Optional[str] = None
|
||||
ssl_certificate: Optional[str] = None
|
||||
ssl_ecdh_curve: Optional[
|
||||
str
|
||||
] = None # Set to 'X25519' to disable PQC and improve performance
|
||||
ssl_ecdh_curve: Optional[str] = (
|
||||
None # Set to 'X25519' to disable PQC and improve performance
|
||||
)
|
||||
disable_streaming_logging: bool = False
|
||||
disable_token_counter: bool = False
|
||||
disable_add_transform_inline_image_block: bool = False
|
||||
@ -330,20 +330,24 @@ enable_loadbalancing_on_batch_endpoints: Optional[bool] = None
|
||||
enable_caching_on_provider_specific_optional_params: bool = (
|
||||
False # feature-flag for caching on optional params - e.g. 'top_k'
|
||||
)
|
||||
caching: bool = False # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
caching_with_models: bool = False # # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
cache: Optional[
|
||||
"Cache"
|
||||
] = None # cache object <- use this - https://docs.litellm.ai/docs/caching
|
||||
caching: bool = (
|
||||
False # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
)
|
||||
caching_with_models: bool = (
|
||||
False # # Not used anymore, will be removed in next MAJOR release - https://github.com/BerriAI/litellm/discussions/648
|
||||
)
|
||||
cache: Optional["Cache"] = (
|
||||
None # cache object <- use this - https://docs.litellm.ai/docs/caching
|
||||
)
|
||||
default_in_memory_ttl: Optional[float] = None
|
||||
default_redis_ttl: Optional[float] = None
|
||||
default_redis_batch_cache_expiry: Optional[float] = None
|
||||
model_alias_map: Dict[str, str] = {}
|
||||
model_group_settings: Optional["ModelGroupSettings"] = None
|
||||
max_budget: float = 0.0 # set the max budget across all providers
|
||||
budget_duration: Optional[
|
||||
str
|
||||
] = None # proxy only - resets budget after fixed duration. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
|
||||
budget_duration: Optional[str] = (
|
||||
None # proxy only - resets budget after fixed duration. You can set duration as seconds ("30s"), minutes ("30m"), hours ("30h"), days ("30d").
|
||||
)
|
||||
default_soft_budget: float = (
|
||||
DEFAULT_SOFT_BUDGET # by default all litellm proxy keys have a soft budget of 50.0
|
||||
)
|
||||
@ -352,7 +356,9 @@ forward_traceparent_to_llm_provider: bool = False
|
||||
|
||||
_current_cost = 0.0 # private variable, used if max budget is set
|
||||
error_logs: Dict = {}
|
||||
add_function_to_prompt: bool = False # if function calling not supported by api, append function call details to system prompt
|
||||
add_function_to_prompt: bool = (
|
||||
False # if function calling not supported by api, append function call details to system prompt
|
||||
)
|
||||
client_session: Optional[httpx.Client] = None
|
||||
aclient_session: Optional[httpx.AsyncClient] = None
|
||||
model_fallbacks: Optional[List] = None # Deprecated for 'litellm.fallbacks'
|
||||
@ -399,7 +405,9 @@ prometheus_emit_stream_label: bool = False
|
||||
disable_add_prefix_to_prompt: bool = (
|
||||
False # used by anthropic, to disable adding prefix to prompt
|
||||
)
|
||||
disable_copilot_system_to_assistant: bool = False # If false (default), converts all 'system' role messages to 'assistant' for GitHub Copilot compatibility. Set to true to disable this behavior.
|
||||
disable_copilot_system_to_assistant: bool = (
|
||||
False # If false (default), converts all 'system' role messages to 'assistant' for GitHub Copilot compatibility. Set to true to disable this behavior.
|
||||
)
|
||||
public_mcp_servers: Optional[List[str]] = None
|
||||
public_model_groups: Optional[List[str]] = None
|
||||
public_agent_groups: Optional[List[str]] = None
|
||||
@ -408,9 +416,9 @@ public_agent_groups: Optional[List[str]] = None
|
||||
# Old format: { "displayName": "url" } (for backward compatibility)
|
||||
public_model_groups_links: Dict[str, Union[str, Dict[str, Any]]] = {}
|
||||
#### REQUEST PRIORITIZATION #######
|
||||
priority_reservation: Optional[
|
||||
Dict[str, Union[float, "PriorityReservationDict"]]
|
||||
] = None
|
||||
priority_reservation: Optional[Dict[str, Union[float, "PriorityReservationDict"]]] = (
|
||||
None
|
||||
)
|
||||
# priority_reservation_settings is lazy-loaded via __getattr__
|
||||
# Only declare for type checking - at runtime __getattr__ handles it
|
||||
if TYPE_CHECKING:
|
||||
@ -418,13 +426,17 @@ if TYPE_CHECKING:
|
||||
|
||||
|
||||
######## Networking Settings ########
|
||||
use_aiohttp_transport: bool = True # Older variable, aiohttp is now the default. use disable_aiohttp_transport instead.
|
||||
use_aiohttp_transport: bool = (
|
||||
True # Older variable, aiohttp is now the default. use disable_aiohttp_transport instead.
|
||||
)
|
||||
aiohttp_trust_env: bool = False # set to true to use HTTP_ Proxy settings
|
||||
disable_aiohttp_transport: bool = False # Set this to true to use httpx instead
|
||||
disable_aiohttp_trust_env: bool = (
|
||||
False # When False, aiohttp will respect HTTP(S)_PROXY env vars
|
||||
)
|
||||
force_ipv4: bool = False # when True, litellm will force ipv4 for all LLM requests. Some users have seen httpx ConnectionError when using ipv6.
|
||||
force_ipv4: bool = (
|
||||
False # when True, litellm will force ipv4 for all LLM requests. Some users have seen httpx ConnectionError when using ipv6.
|
||||
)
|
||||
network_mock: bool = False # When True, use mock transport — no real network calls
|
||||
|
||||
####### STOP SEQUENCE LIMIT #######
|
||||
@ -439,13 +451,13 @@ context_window_fallbacks: Optional[List] = None
|
||||
content_policy_fallbacks: Optional[List] = None
|
||||
allowed_fails: int = 3
|
||||
allow_dynamic_callback_disabling: bool = True
|
||||
num_retries_per_request: Optional[
|
||||
int
|
||||
] = None # for the request overall (incl. fallbacks + model retries)
|
||||
num_retries_per_request: Optional[int] = (
|
||||
None # for the request overall (incl. fallbacks + model retries)
|
||||
)
|
||||
####### SECRET MANAGERS #####################
|
||||
secret_manager_client: Optional[
|
||||
Any
|
||||
] = None # list of instantiated key management clients - e.g. azure kv, infisical, etc.
|
||||
secret_manager_client: Optional[Any] = (
|
||||
None # list of instantiated key management clients - e.g. azure kv, infisical, etc.
|
||||
)
|
||||
_google_kms_resource_name: Optional[str] = None
|
||||
_key_management_system: Optional["KeyManagementSystem"] = None
|
||||
# Note: KeyManagementSettings must be eagerly imported because _key_management_settings
|
||||
@ -458,12 +470,12 @@ output_parse_pii: bool = False
|
||||
from litellm.litellm_core_utils.get_model_cost_map import get_model_cost_map
|
||||
|
||||
model_cost = get_model_cost_map(url=model_cost_map_url)
|
||||
cost_discount_config: Dict[
|
||||
str, float
|
||||
] = {} # Provider-specific cost discounts {"vertex_ai": 0.05} = 5% discount
|
||||
cost_margin_config: Dict[
|
||||
str, Union[float, Dict[str, float]]
|
||||
] = {} # Provider-specific or global cost margins. Examples:
|
||||
cost_discount_config: Dict[str, float] = (
|
||||
{}
|
||||
) # Provider-specific cost discounts {"vertex_ai": 0.05} = 5% discount
|
||||
cost_margin_config: Dict[str, Union[float, Dict[str, float]]] = (
|
||||
{}
|
||||
) # Provider-specific or global cost margins. Examples:
|
||||
# Percentage: {"openai": 0.10} = 10% margin
|
||||
# Fixed: {"openai": {"fixed_amount": 0.001}} = $0.001 per request
|
||||
# Global: {"global": 0.05} = 5% global margin on all providers
|
||||
@ -1313,12 +1325,12 @@ from . import rag
|
||||
from .types.llms.custom_llm import CustomLLMItem
|
||||
|
||||
custom_provider_map: List[CustomLLMItem] = []
|
||||
_custom_providers: List[
|
||||
str
|
||||
] = [] # internal helper util, used to track names of custom providers
|
||||
disable_hf_tokenizer_download: Optional[
|
||||
bool
|
||||
] = None # disable huggingface tokenizer download. Defaults to openai clk100
|
||||
_custom_providers: List[str] = (
|
||||
[]
|
||||
) # internal helper util, used to track names of custom providers
|
||||
disable_hf_tokenizer_download: Optional[bool] = (
|
||||
None # disable huggingface tokenizer download. Defaults to openai clk100
|
||||
)
|
||||
global_disable_no_log_param: bool = False
|
||||
|
||||
### CLI UTILITIES ###
|
||||
|
||||
@ -14,6 +14,7 @@ How it works:
|
||||
This makes importing litellm much faster because we don't load heavy dependencies
|
||||
until they're actually needed.
|
||||
"""
|
||||
|
||||
import importlib
|
||||
import sys
|
||||
from typing import Any, Optional, cast, Callable
|
||||
|
||||
@ -120,9 +120,9 @@ def _get_a2a_model_info(a2a_client: Any, kwargs: Dict[str, Any]) -> str:
|
||||
litellm_logging_obj.model = model
|
||||
litellm_logging_obj.custom_llm_provider = custom_llm_provider
|
||||
litellm_logging_obj.model_call_details["model"] = model
|
||||
litellm_logging_obj.model_call_details[
|
||||
"custom_llm_provider"
|
||||
] = custom_llm_provider
|
||||
litellm_logging_obj.model_call_details["custom_llm_provider"] = (
|
||||
custom_llm_provider
|
||||
)
|
||||
|
||||
return agent_name
|
||||
|
||||
|
||||
@ -99,9 +99,7 @@ class BedrockAgentCoreA2AHandler:
|
||||
)
|
||||
)
|
||||
|
||||
verbose_logger.info(
|
||||
f"BedrockAgentCore A2A: Sending streaming request to {url}"
|
||||
)
|
||||
verbose_logger.info(f"BedrockAgentCore A2A: Sending streaming request to {url}")
|
||||
|
||||
client = get_async_httpx_client(
|
||||
llm_provider=cast(Any, httpxSpecialProvider.A2AProvider),
|
||||
|
||||
@ -168,9 +168,9 @@ class A2AStreamingIterator:
|
||||
result: Dict[str, Any] = {
|
||||
"id": getattr(self.request, "id", "unknown"),
|
||||
"jsonrpc": "2.0",
|
||||
"usage": usage.model_dump()
|
||||
if hasattr(usage, "model_dump")
|
||||
else dict(usage),
|
||||
"usage": (
|
||||
usage.model_dump() if hasattr(usage, "model_dump") else dict(usage)
|
||||
),
|
||||
}
|
||||
|
||||
# Add final chunk result if available
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
Anthropic module for LiteLLM
|
||||
"""
|
||||
|
||||
from .messages import acreate, create
|
||||
|
||||
__all__ = ["acreate", "create"]
|
||||
|
||||
@ -38,7 +38,7 @@ async def acreate(
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
container: Optional[Dict] = None,
|
||||
**kwargs
|
||||
**kwargs,
|
||||
) -> Union[AnthropicMessagesResponse, AsyncIterator]:
|
||||
"""
|
||||
Async wrapper for Anthropic's messages API
|
||||
@ -97,7 +97,7 @@ def create(
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
container: Optional[Dict] = None,
|
||||
**kwargs
|
||||
**kwargs,
|
||||
) -> Union[
|
||||
AnthropicMessagesResponse,
|
||||
AsyncIterator[Any],
|
||||
|
||||
@ -78,7 +78,9 @@ class CachingHandlerResponse(BaseModel):
|
||||
|
||||
cached_result: Optional[Any] = None
|
||||
final_embedding_cached_response: Optional[EmbeddingResponse] = None
|
||||
embedding_all_elements_cache_hit: bool = False # this is set to True when all elements in the list have a cache hit in the embedding cache, if true return the final_embedding_cached_response no need to make an API call
|
||||
embedding_all_elements_cache_hit: bool = (
|
||||
False # this is set to True when all elements in the list have a cache hit in the embedding cache, if true return the final_embedding_cached_response no need to make an API call
|
||||
)
|
||||
|
||||
|
||||
in_memory_cache_obj = InMemoryCache()
|
||||
@ -1014,9 +1016,9 @@ class LLMCachingHandler:
|
||||
}
|
||||
|
||||
if litellm.cache is not None:
|
||||
litellm_params[
|
||||
"preset_cache_key"
|
||||
] = litellm.cache._get_preset_cache_key_from_kwargs(**kwargs)
|
||||
litellm_params["preset_cache_key"] = (
|
||||
litellm.cache._get_preset_cache_key_from_kwargs(**kwargs)
|
||||
)
|
||||
else:
|
||||
litellm_params["preset_cache_key"] = None
|
||||
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""GCS Cache implementation
|
||||
Supports syncing responses to Google Cloud Storage Buckets using HTTP requests.
|
||||
"""
|
||||
|
||||
import json
|
||||
import asyncio
|
||||
from typing import Optional
|
||||
|
||||
@ -142,9 +142,7 @@ class ResponsesToCompletionBridgeHandler:
|
||||
custom_llm_provider=custom_llm_provider,
|
||||
)
|
||||
|
||||
def completion(
|
||||
self, *args, **kwargs
|
||||
) -> Union[
|
||||
def completion(self, *args, **kwargs) -> Union[
|
||||
Coroutine[Any, Any, Union["ModelResponse", "CustomStreamWrapper"]],
|
||||
"ModelResponse",
|
||||
"CustomStreamWrapper",
|
||||
|
||||
@ -300,10 +300,10 @@ class LiteLLMResponsesTransformationHandler(CompletionTransformationBridge):
|
||||
if key in ("max_tokens", "max_completion_tokens"):
|
||||
responses_api_request["max_output_tokens"] = value
|
||||
elif key == "tools" and value is not None:
|
||||
responses_api_request[
|
||||
"tools"
|
||||
] = self._convert_tools_to_responses_format(
|
||||
cast(List[Dict[str, Any]], value)
|
||||
responses_api_request["tools"] = (
|
||||
self._convert_tools_to_responses_format(
|
||||
cast(List[Dict[str, Any]], value)
|
||||
)
|
||||
)
|
||||
elif key == "response_format":
|
||||
text_format = self._transform_response_format_to_text_format(value)
|
||||
@ -506,9 +506,11 @@ class LiteLLMResponsesTransformationHandler(CompletionTransformationBridge):
|
||||
annotations=annotations,
|
||||
reasoning_items=cast(
|
||||
Optional[List[ChatCompletionReasoningItem]],
|
||||
[pending_reasoning_item]
|
||||
if pending_reasoning_item is not None
|
||||
else None,
|
||||
(
|
||||
[pending_reasoning_item]
|
||||
if pending_reasoning_item is not None
|
||||
else None
|
||||
),
|
||||
),
|
||||
)
|
||||
|
||||
@ -566,9 +568,11 @@ class LiteLLMResponsesTransformationHandler(CompletionTransformationBridge):
|
||||
reasoning_content=reasoning_content,
|
||||
reasoning_items=cast(
|
||||
Optional[List[ChatCompletionReasoningItem]],
|
||||
[pending_reasoning_item]
|
||||
if pending_reasoning_item is not None
|
||||
else None,
|
||||
(
|
||||
[pending_reasoning_item]
|
||||
if pending_reasoning_item is not None
|
||||
else None
|
||||
),
|
||||
),
|
||||
)
|
||||
choices.append(
|
||||
@ -1154,9 +1158,9 @@ class OpenAiResponsesToChatCompletionStreamIterator(BaseModelResponseIterator):
|
||||
)
|
||||
|
||||
if provider_specific_fields:
|
||||
function_chunk[
|
||||
"provider_specific_fields"
|
||||
] = provider_specific_fields
|
||||
function_chunk["provider_specific_fields"] = (
|
||||
provider_specific_fields
|
||||
)
|
||||
|
||||
tool_call_index = parsed_chunk.get("output_index", 0)
|
||||
tool_call_chunk = ChatCompletionToolCallChunk(
|
||||
@ -1229,9 +1233,9 @@ class OpenAiResponsesToChatCompletionStreamIterator(BaseModelResponseIterator):
|
||||
|
||||
# Add provider_specific_fields to function if present
|
||||
if provider_specific_fields:
|
||||
function_chunk[
|
||||
"provider_specific_fields"
|
||||
] = provider_specific_fields
|
||||
function_chunk["provider_specific_fields"] = (
|
||||
provider_specific_fields
|
||||
)
|
||||
|
||||
tool_call_index = parsed_chunk.get("output_index", 0)
|
||||
tool_call_chunk = ChatCompletionToolCallChunk(
|
||||
|
||||
@ -247,9 +247,11 @@ def compress(
|
||||
messages=compressed_messages,
|
||||
original_tokens=original_tokens,
|
||||
compressed_tokens=compressed_tokens,
|
||||
compression_ratio=round(1 - (compressed_tokens / original_tokens), 4)
|
||||
if original_tokens > 0
|
||||
else 0.0,
|
||||
compression_ratio=(
|
||||
round(1 - (compressed_tokens / original_tokens), 4)
|
||||
if original_tokens > 0
|
||||
else 0.0
|
||||
),
|
||||
cache=cache,
|
||||
tools=tools,
|
||||
)
|
||||
|
||||
@ -90,10 +90,10 @@ def create_sync_endpoint_function(endpoint_config: Dict) -> Callable:
|
||||
custom_llm_provider=resolved_custom_llm_provider,
|
||||
litellm_params=litellm_params,
|
||||
)
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
|
||||
@ -168,7 +168,10 @@ def create_container(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[ContainerObject, Coroutine[Any, Any, ContainerObject],]:
|
||||
) -> Union[
|
||||
ContainerObject,
|
||||
Coroutine[Any, Any, ContainerObject],
|
||||
]:
|
||||
"""Create a container using the OpenAI Container API.
|
||||
|
||||
Currently supports OpenAI
|
||||
@ -208,10 +211,10 @@ def create_container(
|
||||
**kwargs,
|
||||
)
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
@ -260,7 +263,7 @@ def create_container(
|
||||
timeout=timeout or DEFAULT_REQUEST_TIMEOUT,
|
||||
_is_async=_is_async,
|
||||
)
|
||||
|
||||
|
||||
# Encode container_id with provider/model metadata for routing
|
||||
if isinstance(container_obj, ContainerObject):
|
||||
container_obj = ContainerRequestUtils.encode_container_id_in_response(
|
||||
@ -269,7 +272,7 @@ def create_container(
|
||||
litellm_metadata=kwargs.get("litellm_metadata"),
|
||||
extra_body=extra_body,
|
||||
)
|
||||
|
||||
|
||||
return container_obj
|
||||
|
||||
except Exception as e:
|
||||
@ -405,7 +408,10 @@ def list_containers(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[ContainerListResponse, Coroutine[Any, Any, ContainerListResponse],]:
|
||||
) -> Union[
|
||||
ContainerListResponse,
|
||||
Coroutine[Any, Any, ContainerListResponse],
|
||||
]:
|
||||
"""List containers using the OpenAI Container API.
|
||||
|
||||
Currently supports OpenAI
|
||||
@ -434,10 +440,10 @@ def list_containers(
|
||||
**kwargs,
|
||||
)
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
@ -601,7 +607,10 @@ def retrieve_container(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[ContainerObject, Coroutine[Any, Any, ContainerObject],]:
|
||||
) -> Union[
|
||||
ContainerObject,
|
||||
Coroutine[Any, Any, ContainerObject],
|
||||
]:
|
||||
"""Retrieve a container using the OpenAI Container API.
|
||||
|
||||
Currently supports OpenAI
|
||||
@ -630,7 +639,7 @@ def retrieve_container(
|
||||
api_version=api_version,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
# Decode container ID and extract provider info
|
||||
original_container_id, resolved_custom_llm_provider, litellm_params = (
|
||||
decode_managed_container_id_for_request(
|
||||
@ -643,10 +652,10 @@ def retrieve_container(
|
||||
was_encoded = original_container_id != container_id
|
||||
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
@ -678,7 +687,7 @@ def retrieve_container(
|
||||
timeout=timeout or DEFAULT_REQUEST_TIMEOUT,
|
||||
_is_async=_is_async,
|
||||
)
|
||||
|
||||
|
||||
# Encode container_id with provider/model metadata for routing
|
||||
# If input was encoded, preserve encoding in output using the decoded model_id
|
||||
if isinstance(container_obj, ContainerObject):
|
||||
@ -691,14 +700,14 @@ def retrieve_container(
|
||||
if "model_info" not in litellm_metadata:
|
||||
litellm_metadata["model_info"] = {}
|
||||
litellm_metadata["model_info"]["id"] = litellm_params["model_id"]
|
||||
|
||||
|
||||
container_obj = ContainerRequestUtils.encode_container_id_in_response(
|
||||
response_obj=container_obj,
|
||||
custom_llm_provider=resolved_custom_llm_provider,
|
||||
litellm_metadata=litellm_metadata,
|
||||
extra_body=None,
|
||||
)
|
||||
|
||||
|
||||
return container_obj
|
||||
|
||||
except Exception as e:
|
||||
@ -822,7 +831,10 @@ def delete_container(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[DeleteContainerResult, Coroutine[Any, Any, DeleteContainerResult],]:
|
||||
) -> Union[
|
||||
DeleteContainerResult,
|
||||
Coroutine[Any, Any, DeleteContainerResult],
|
||||
]:
|
||||
"""Delete a container using the OpenAI Container API.
|
||||
|
||||
Currently supports OpenAI
|
||||
@ -851,7 +863,7 @@ def delete_container(
|
||||
api_version=api_version,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
# Decode container ID and extract provider info
|
||||
original_container_id, resolved_custom_llm_provider, litellm_params = (
|
||||
decode_managed_container_id_for_request(
|
||||
@ -864,10 +876,10 @@ def delete_container(
|
||||
was_encoded = original_container_id != container_id
|
||||
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
@ -899,7 +911,7 @@ def delete_container(
|
||||
timeout=timeout or DEFAULT_REQUEST_TIMEOUT,
|
||||
_is_async=_is_async,
|
||||
)
|
||||
|
||||
|
||||
# Encode container_id in response with provider/model metadata for routing
|
||||
# If input was encoded, preserve encoding in output using the decoded model_id
|
||||
if isinstance(delete_result, DeleteContainerResult):
|
||||
@ -912,14 +924,14 @@ def delete_container(
|
||||
if "model_info" not in litellm_metadata:
|
||||
litellm_metadata["model_info"] = {}
|
||||
litellm_metadata["model_info"]["id"] = litellm_params["model_id"]
|
||||
|
||||
|
||||
delete_result = ContainerRequestUtils.encode_container_id_in_response(
|
||||
response_obj=delete_result,
|
||||
custom_llm_provider=resolved_custom_llm_provider,
|
||||
litellm_metadata=litellm_metadata,
|
||||
extra_body=None,
|
||||
)
|
||||
|
||||
|
||||
return delete_result
|
||||
|
||||
except Exception as e:
|
||||
@ -1057,7 +1069,10 @@ def list_container_files(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[ContainerFileListResponse, Coroutine[Any, Any, ContainerFileListResponse],]:
|
||||
) -> Union[
|
||||
ContainerFileListResponse,
|
||||
Coroutine[Any, Any, ContainerFileListResponse],
|
||||
]:
|
||||
"""List files in a container using the OpenAI Container API.
|
||||
|
||||
Currently supports OpenAI
|
||||
@ -1086,7 +1101,7 @@ def list_container_files(
|
||||
api_version=api_version,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
# Decode container ID and extract provider info
|
||||
original_container_id, resolved_custom_llm_provider, litellm_params = (
|
||||
decode_managed_container_id_for_request(
|
||||
@ -1095,12 +1110,12 @@ def list_container_files(
|
||||
litellm_params=litellm_params,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
@ -1285,7 +1300,10 @@ def upload_container_file(
|
||||
extra_query: Optional[Dict[str, Any]] = None,
|
||||
extra_body: Optional[Dict[str, Any]] = None,
|
||||
**kwargs,
|
||||
) -> Union[ContainerFileObject, Coroutine[Any, Any, ContainerFileObject],]:
|
||||
) -> Union[
|
||||
ContainerFileObject,
|
||||
Coroutine[Any, Any, ContainerFileObject],
|
||||
]:
|
||||
"""Upload a file to a container using the OpenAI Container API.
|
||||
|
||||
This endpoint allows uploading files directly to a container session,
|
||||
@ -1343,7 +1361,7 @@ def upload_container_file(
|
||||
api_version=api_version,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
# Decode container ID and extract provider info
|
||||
original_container_id, resolved_custom_llm_provider, litellm_params = (
|
||||
decode_managed_container_id_for_request(
|
||||
@ -1352,12 +1370,12 @@ def upload_container_file(
|
||||
litellm_params=litellm_params,
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
# get provider config
|
||||
container_provider_config: Optional[
|
||||
BaseContainerConfig
|
||||
] = ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
container_provider_config: Optional[BaseContainerConfig] = (
|
||||
ProviderConfigManager.get_provider_container_config(
|
||||
provider=litellm.LlmProviders(resolved_custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if container_provider_config is None:
|
||||
|
||||
@ -32,6 +32,7 @@ def decode_managed_container_id_for_request(
|
||||
|
||||
return original_container_id, custom_llm_provider, litellm_params
|
||||
|
||||
|
||||
T = TypeVar("T")
|
||||
|
||||
|
||||
@ -129,14 +130,14 @@ class ContainerRequestUtils:
|
||||
litellm_metadata = litellm_metadata or {}
|
||||
model_info: Dict[str, Any] = litellm_metadata.get("model_info", {}) or {}
|
||||
model_id = model_info.get("id")
|
||||
|
||||
|
||||
# Check if we should encode based on routing metadata
|
||||
should_encode = False
|
||||
|
||||
|
||||
# Case 1: Router/proxy usage (model_id from router)
|
||||
if model_id is not None:
|
||||
should_encode = True
|
||||
|
||||
|
||||
# Case 2: target_model_names in extra_body (model-specific routing)
|
||||
if extra_body and "target_model_names" in extra_body:
|
||||
should_encode = True
|
||||
@ -148,7 +149,7 @@ class ContainerRequestUtils:
|
||||
model_id = target_models.split(",")[0].strip()
|
||||
elif isinstance(target_models, list) and len(target_models) > 0:
|
||||
model_id = str(target_models[0]).strip()
|
||||
|
||||
|
||||
# Only encode if we have routing metadata
|
||||
if should_encode and response_obj and hasattr(response_obj, "id"):
|
||||
encoded_id = ResponsesAPIRequestUtils._build_container_id(
|
||||
|
||||
@ -545,10 +545,9 @@ def cost_per_token( # noqa: PLR0915
|
||||
model=model, custom_llm_provider=custom_llm_provider
|
||||
)
|
||||
|
||||
if (
|
||||
(model_info.get("input_cost_per_token") or 0.0) > 0
|
||||
or (model_info.get("output_cost_per_token") or 0.0) > 0
|
||||
):
|
||||
if (model_info.get("input_cost_per_token") or 0.0) > 0 or (
|
||||
model_info.get("output_cost_per_token") or 0.0
|
||||
) > 0:
|
||||
return generic_cost_per_token(
|
||||
model=model,
|
||||
usage=usage_block,
|
||||
@ -1141,9 +1140,9 @@ def completion_cost( # noqa: PLR0915
|
||||
or isinstance(completion_response, dict)
|
||||
): # tts returns a custom class
|
||||
if isinstance(completion_response, dict):
|
||||
usage_obj: Optional[
|
||||
Union[dict, Usage]
|
||||
] = completion_response.get("usage", {})
|
||||
usage_obj: Optional[Union[dict, Usage]] = (
|
||||
completion_response.get("usage", {})
|
||||
)
|
||||
else:
|
||||
usage_obj = getattr(completion_response, "usage", {})
|
||||
if isinstance(usage_obj, BaseModel) and not _is_known_usage_objects(
|
||||
@ -1606,11 +1605,23 @@ def completion_cost( # noqa: PLR0915
|
||||
_cache_read_cost: Optional[float] = None
|
||||
_cache_creation_cost: Optional[float] = None
|
||||
if cost_per_token_usage_object is not None:
|
||||
_cr = getattr(cost_per_token_usage_object, "cache_read_input_tokens", None) or (cost_per_token_usage_object.model_extra or {}).get("cache_read_input_tokens")
|
||||
_cc = getattr(cost_per_token_usage_object, "cache_creation_input_tokens", None) or (cost_per_token_usage_object.model_extra or {}).get("cache_creation_input_tokens")
|
||||
_cr = getattr(
|
||||
cost_per_token_usage_object, "cache_read_input_tokens", None
|
||||
) or (cost_per_token_usage_object.model_extra or {}).get(
|
||||
"cache_read_input_tokens"
|
||||
)
|
||||
_cc = getattr(
|
||||
cost_per_token_usage_object,
|
||||
"cache_creation_input_tokens",
|
||||
None,
|
||||
) or (cost_per_token_usage_object.model_extra or {}).get(
|
||||
"cache_creation_input_tokens"
|
||||
)
|
||||
if (_cr or _cc) and model:
|
||||
try:
|
||||
_mi = litellm.get_model_info(model=model, custom_llm_provider=custom_llm_provider)
|
||||
_mi = litellm.get_model_info(
|
||||
model=model, custom_llm_provider=custom_llm_provider
|
||||
)
|
||||
_cr_rate = _mi.get("cache_read_input_token_cost")
|
||||
if _cr and _cr_rate is not None:
|
||||
_cache_read_cost = float(_cr) * float(_cr_rate)
|
||||
|
||||
@ -152,10 +152,10 @@ def create_eval(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -343,10 +343,10 @@ def list_evals(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -513,10 +513,10 @@ def get_eval(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -682,10 +682,10 @@ def update_eval(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -893,10 +893,10 @@ def delete_eval(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1047,10 +1047,10 @@ def cancel_eval(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1230,10 +1230,10 @@ def create_run(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1418,10 +1418,10 @@ def list_runs(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1592,10 +1592,10 @@ def get_run(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1752,10 +1752,10 @@ def cancel_run(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
@ -1921,10 +1921,10 @@ def delete_run(
|
||||
custom_llm_provider = "openai"
|
||||
|
||||
# Get provider config
|
||||
evals_api_provider_config: Optional[
|
||||
BaseEvalsAPIConfig
|
||||
] = ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
evals_api_provider_config: Optional[BaseEvalsAPIConfig] = (
|
||||
ProviderConfigManager.get_provider_evals_api_config( # type: ignore
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if evals_api_provider_config is None:
|
||||
|
||||
@ -281,7 +281,7 @@ class Timeout(openai.APITimeoutError): # type: ignore
|
||||
return _message
|
||||
|
||||
|
||||
class PermissionDeniedError(openai.PermissionDeniedError): # type:ignore
|
||||
class PermissionDeniedError(openai.PermissionDeniedError): # type: ignore
|
||||
def __init__(
|
||||
self,
|
||||
message,
|
||||
@ -847,6 +847,7 @@ class BudgetExceededError(Exception):
|
||||
):
|
||||
self.current_cost = current_cost
|
||||
self.max_budget = max_budget
|
||||
self.status_code = 429
|
||||
message = (
|
||||
message
|
||||
or f"Budget has been exceeded! Current cost: {current_cost}, Max budget: {max_budget}"
|
||||
|
||||
@ -10,7 +10,7 @@ import contextvars
|
||||
import time
|
||||
import uuid as uuid_module
|
||||
from functools import partial
|
||||
from typing import Any,Coroutine, Dict, Literal, Optional, Union, cast
|
||||
from typing import Any, Coroutine, Dict, Literal, Optional, Union, cast
|
||||
|
||||
import httpx
|
||||
|
||||
@ -53,7 +53,10 @@ from litellm.types.llms.openai import (
|
||||
OpenAIFileObject,
|
||||
)
|
||||
from litellm.types.router import *
|
||||
from litellm.types.utils import OPENAI_COMPATIBLE_BATCH_AND_FILES_PROVIDERS, LlmProviders
|
||||
from litellm.types.utils import (
|
||||
OPENAI_COMPATIBLE_BATCH_AND_FILES_PROVIDERS,
|
||||
LlmProviders,
|
||||
)
|
||||
from litellm.utils import (
|
||||
ProviderConfigManager,
|
||||
client,
|
||||
@ -73,6 +76,8 @@ def _should_sdk_support_streaming(
|
||||
Return whether file content streaming is supported for the provider.
|
||||
"""
|
||||
return custom_llm_provider in OPENAI_COMPATIBLE_BATCH_AND_FILES_PROVIDERS
|
||||
|
||||
|
||||
openai_files_instance = OpenAIFilesAPI()
|
||||
azure_files_instance = AzureOpenAIFilesAPI()
|
||||
vertex_ai_files_instance = VertexAIFilesHandler()
|
||||
@ -1094,9 +1099,10 @@ def file_content_streaming(
|
||||
)
|
||||
|
||||
if asyncio.iscoroutine(response):
|
||||
|
||||
async def _await_and_wrap() -> FileContentStreamingResult:
|
||||
return _wrap_streaming_result(await response)
|
||||
|
||||
return _await_and_wrap()
|
||||
|
||||
return _wrap_streaming_result(response)
|
||||
return _wrap_streaming_result(response)
|
||||
|
||||
@ -1,6 +1,15 @@
|
||||
import datetime
|
||||
import traceback
|
||||
from typing import TYPE_CHECKING, Any, AsyncIterator, Dict, Iterator, Optional, Union, cast
|
||||
from typing import (
|
||||
TYPE_CHECKING,
|
||||
Any,
|
||||
AsyncIterator,
|
||||
Dict,
|
||||
Iterator,
|
||||
Optional,
|
||||
Union,
|
||||
cast,
|
||||
)
|
||||
|
||||
import anyio
|
||||
from litellm.files.types import FileContentProvider
|
||||
@ -11,6 +20,7 @@ if TYPE_CHECKING:
|
||||
)
|
||||
from litellm.types.utils import StandardLoggingHiddenParams, StandardLoggingPayload
|
||||
|
||||
|
||||
class FileContentStreamingResponse:
|
||||
"""
|
||||
Iterator wrapper for file content streaming that carries LiteLLM metadata
|
||||
@ -84,7 +94,9 @@ class FileContentStreamingResponse:
|
||||
self._close_completed = True
|
||||
self._logging_completed = True
|
||||
stream_to_close = self.stream_iterator
|
||||
self.stream_iterator = cast(Union[Iterator[bytes], AsyncIterator[bytes]], iter(()))
|
||||
self.stream_iterator = cast(
|
||||
Union[Iterator[bytes], AsyncIterator[bytes]], iter(())
|
||||
)
|
||||
|
||||
# Shield cleanup from request cancellation so upstream HTTP connections
|
||||
# are released promptly on client disconnects.
|
||||
@ -103,7 +115,9 @@ class FileContentStreamingResponse:
|
||||
self._close_completed = True
|
||||
self._logging_completed = True
|
||||
stream_to_close = self.stream_iterator
|
||||
self.stream_iterator = cast(Union[Iterator[bytes], AsyncIterator[bytes]], iter(()))
|
||||
self.stream_iterator = cast(
|
||||
Union[Iterator[bytes], AsyncIterator[bytes]], iter(())
|
||||
)
|
||||
|
||||
if hasattr(stream_to_close, "close"):
|
||||
cast(Iterator[bytes], stream_to_close).close() # type: ignore[attr-defined]
|
||||
|
||||
@ -210,7 +210,10 @@ def image_generation( # noqa: PLR0915
|
||||
api_version: Optional[str] = None,
|
||||
custom_llm_provider=None,
|
||||
**kwargs,
|
||||
) -> Union[ImageResponse, Coroutine[Any, Any, ImageResponse],]:
|
||||
) -> Union[
|
||||
ImageResponse,
|
||||
Coroutine[Any, Any, ImageResponse],
|
||||
]:
|
||||
"""
|
||||
Maps the https://api.openai.com/v1/images/generations endpoint.
|
||||
|
||||
@ -864,11 +867,11 @@ def image_edit( # noqa: PLR0915
|
||||
)
|
||||
|
||||
# get provider config
|
||||
image_edit_provider_config: Optional[
|
||||
BaseImageEditConfig
|
||||
] = ProviderConfigManager.get_provider_image_edit_config(
|
||||
model=model,
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
image_edit_provider_config: Optional[BaseImageEditConfig] = (
|
||||
ProviderConfigManager.get_provider_image_edit_config(
|
||||
model=model,
|
||||
provider=litellm.LlmProviders(custom_llm_provider),
|
||||
)
|
||||
)
|
||||
|
||||
if image_edit_provider_config is None:
|
||||
@ -876,20 +879,20 @@ def image_edit( # noqa: PLR0915
|
||||
|
||||
local_vars.update(kwargs)
|
||||
# Get ImageEditOptionalRequestParams with only valid parameters
|
||||
image_edit_optional_params: ImageEditOptionalRequestParams = (
|
||||
_get_ImageEditRequestUtils().get_requested_image_edit_optional_param(
|
||||
local_vars
|
||||
)
|
||||
image_edit_optional_params: (
|
||||
ImageEditOptionalRequestParams
|
||||
) = _get_ImageEditRequestUtils().get_requested_image_edit_optional_param(
|
||||
local_vars
|
||||
)
|
||||
# Get optional parameters for the responses API
|
||||
image_edit_request_params: Dict = (
|
||||
_get_ImageEditRequestUtils().get_optional_params_image_edit(
|
||||
model=model,
|
||||
image_edit_provider_config=image_edit_provider_config,
|
||||
image_edit_optional_params=image_edit_optional_params,
|
||||
drop_params=kwargs.get("drop_params"),
|
||||
additional_drop_params=kwargs.get("additional_drop_params"),
|
||||
)
|
||||
image_edit_request_params: (
|
||||
Dict
|
||||
) = _get_ImageEditRequestUtils().get_optional_params_image_edit(
|
||||
model=model,
|
||||
image_edit_provider_config=image_edit_provider_config,
|
||||
image_edit_optional_params=image_edit_optional_params,
|
||||
drop_params=kwargs.get("drop_params"),
|
||||
additional_drop_params=kwargs.get("additional_drop_params"),
|
||||
)
|
||||
|
||||
# Pre Call logging
|
||||
|
||||
@ -102,10 +102,10 @@ class AlertingHangingRequestCheck:
|
||||
)
|
||||
|
||||
for request_id in hanging_requests:
|
||||
hanging_request_data: Optional[
|
||||
HangingRequestData
|
||||
] = await self.hanging_request_cache.async_get_cache(
|
||||
key=request_id,
|
||||
hanging_request_data: Optional[HangingRequestData] = (
|
||||
await self.hanging_request_cache.async_get_cache(
|
||||
key=request_id,
|
||||
)
|
||||
)
|
||||
|
||||
if hanging_request_data is None:
|
||||
|
||||
@ -852,9 +852,9 @@ class SlackAlerting(CustomBatchLogger):
|
||||
### UNIQUE CACHE KEY ###
|
||||
cache_key = provider + region_name
|
||||
|
||||
outage_value: Optional[
|
||||
ProviderRegionOutageModel
|
||||
] = await self.internal_usage_cache.async_get_cache(key=cache_key)
|
||||
outage_value: Optional[ProviderRegionOutageModel] = (
|
||||
await self.internal_usage_cache.async_get_cache(key=cache_key)
|
||||
)
|
||||
|
||||
# Convert deployment_ids back to set if it was stored as a list
|
||||
if outage_value is not None:
|
||||
@ -1443,9 +1443,9 @@ Model Info:
|
||||
self.alert_to_webhook_url is not None
|
||||
and alert_type in self.alert_to_webhook_url
|
||||
):
|
||||
_digest_webhook: Optional[
|
||||
Union[str, List[str]]
|
||||
] = self.alert_to_webhook_url[alert_type]
|
||||
_digest_webhook: Optional[Union[str, List[str]]] = (
|
||||
self.alert_to_webhook_url[alert_type]
|
||||
)
|
||||
elif self.default_webhook_url is not None:
|
||||
_digest_webhook = self.default_webhook_url
|
||||
else:
|
||||
@ -1499,9 +1499,9 @@ Model Info:
|
||||
self.alert_to_webhook_url is not None
|
||||
and alert_type in self.alert_to_webhook_url
|
||||
):
|
||||
slack_webhook_url: Optional[
|
||||
Union[str, List[str]]
|
||||
] = self.alert_to_webhook_url[alert_type]
|
||||
slack_webhook_url: Optional[Union[str, List[str]]] = (
|
||||
self.alert_to_webhook_url[alert_type]
|
||||
)
|
||||
elif self.default_webhook_url is not None:
|
||||
slack_webhook_url = self.default_webhook_url
|
||||
else:
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
AgentOps integration for LiteLLM - Provides OpenTelemetry tracing for LLM calls
|
||||
"""
|
||||
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional, Dict, Any
|
||||
|
||||
@ -106,10 +106,10 @@ class AnthropicCacheControlHook(CustomPromptManagement):
|
||||
targetted_index += len(messages)
|
||||
|
||||
if 0 <= targetted_index < len(messages):
|
||||
messages[
|
||||
targetted_index
|
||||
] = AnthropicCacheControlHook._safe_insert_cache_control_in_message(
|
||||
messages[targetted_index], control
|
||||
messages[targetted_index] = (
|
||||
AnthropicCacheControlHook._safe_insert_cache_control_in_message(
|
||||
messages[targetted_index], control
|
||||
)
|
||||
)
|
||||
else:
|
||||
verbose_logger.warning(
|
||||
|
||||
@ -178,9 +178,9 @@ class ArizePhoenixLogger(OpenTelemetry): # type: ignore
|
||||
start_time_val = kwargs.get("start_time", kwargs.get("api_call_start_time"))
|
||||
parent_span = self.tracer.start_span(
|
||||
name="litellm_proxy_request",
|
||||
start_time=self._to_ns(start_time_val)
|
||||
if start_time_val is not None
|
||||
else None,
|
||||
start_time=(
|
||||
self._to_ns(start_time_val) if start_time_val is not None else None
|
||||
),
|
||||
context=traceparent_ctx,
|
||||
kind=self.span_kind.SERVER,
|
||||
)
|
||||
|
||||
@ -54,12 +54,12 @@ class AzureBlobStorageLogger(CustomBatchLogger):
|
||||
self._service_client_timeout: Optional[float] = None
|
||||
|
||||
# Internal variables used for Token based authentication
|
||||
self.azure_auth_token: Optional[
|
||||
str
|
||||
] = None # the Azure AD token to use for Azure Storage API requests
|
||||
self.token_expiry: Optional[
|
||||
datetime
|
||||
] = None # the expiry time of the currentAzure AD token
|
||||
self.azure_auth_token: Optional[str] = (
|
||||
None # the Azure AD token to use for Azure Storage API requests
|
||||
)
|
||||
self.token_expiry: Optional[datetime] = (
|
||||
None # the expiry time of the currentAzure AD token
|
||||
)
|
||||
|
||||
asyncio.create_task(self.periodic_flush())
|
||||
self.flush_lock = asyncio.Lock()
|
||||
|
||||
@ -52,9 +52,9 @@ class BraintrustLogger(CustomLogger):
|
||||
"Authorization": "Bearer " + self.api_key,
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
self._project_id_cache: Dict[
|
||||
str, str
|
||||
] = {} # Cache mapping project names to IDs
|
||||
self._project_id_cache: Dict[str, str] = (
|
||||
{}
|
||||
) # Cache mapping project names to IDs
|
||||
self.global_braintrust_http_handler = get_async_httpx_client(
|
||||
llm_provider=httpxSpecialProvider.LoggingCallback
|
||||
)
|
||||
|
||||
@ -402,10 +402,10 @@ class CloudZeroLogger(CustomLogger):
|
||||
from litellm.constants import CLOUDZERO_EXPORT_INTERVAL_MINUTES
|
||||
from litellm.integrations.custom_logger import CustomLogger
|
||||
|
||||
prometheus_loggers: List[
|
||||
CustomLogger
|
||||
] = litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=CloudZeroLogger
|
||||
prometheus_loggers: List[CustomLogger] = (
|
||||
litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=CloudZeroLogger
|
||||
)
|
||||
)
|
||||
# we need to get the initialized prometheus logger instance(s) and call logger.initialize_remaining_budget_metrics() on them
|
||||
verbose_logger.debug("found %s cloudzero loggers", len(prometheus_loggers))
|
||||
|
||||
@ -159,9 +159,9 @@ class CBFTransformer:
|
||||
# CloudZero CBF format with proper column names
|
||||
cbf_record = {
|
||||
# Required CBF fields
|
||||
"time/usage_start": usage_date.isoformat()
|
||||
if usage_date
|
||||
else None, # Required: ISO-formatted UTC datetime
|
||||
"time/usage_start": (
|
||||
usage_date.isoformat() if usage_date else None
|
||||
), # Required: ISO-formatted UTC datetime
|
||||
"cost/cost": float(row.get("spend", 0.0)), # Required: billed cost
|
||||
"resource/id": resource_id, # CZRN (CloudZero Resource Name)
|
||||
# Usage metrics for token consumption
|
||||
@ -182,9 +182,9 @@ class CBFTransformer:
|
||||
|
||||
# Add CZRN components that don't have direct CBF column mappings as resource tags
|
||||
cbf_record["resource/tag:provider"] = provider # CZRN provider component
|
||||
cbf_record[
|
||||
"resource/tag:model"
|
||||
] = cloud_local_id # CZRN cloud-local-id component (model)
|
||||
cbf_record["resource/tag:model"] = (
|
||||
cloud_local_id # CZRN cloud-local-id component (model)
|
||||
)
|
||||
|
||||
# Add resource tags for all dimensions (using resource/tag:<key> format)
|
||||
for key, value in dimensions.items():
|
||||
|
||||
@ -417,7 +417,9 @@ class CustomGuardrail(CustomLogger):
|
||||
"""
|
||||
requested_guardrails = self.get_guardrail_from_metadata(data)
|
||||
disable_global_guardrail = self.get_disable_global_guardrail(data)
|
||||
opted_out_global_guardrails = self.get_opted_out_global_guardrails_from_metadata(data)
|
||||
opted_out_global_guardrails = (
|
||||
self.get_opted_out_global_guardrails_from_metadata(data)
|
||||
)
|
||||
verbose_logger.debug(
|
||||
"inside should_run_guardrail for guardrail=%s event_type= %s guardrail_supported_event_hooks= %s requested_guardrails= %s self.default_on= %s",
|
||||
self.guardrail_name,
|
||||
@ -426,7 +428,10 @@ class CustomGuardrail(CustomLogger):
|
||||
requested_guardrails,
|
||||
self.default_on,
|
||||
)
|
||||
if self.default_on is True and self.guardrail_name in opted_out_global_guardrails:
|
||||
if (
|
||||
self.default_on is True
|
||||
and self.guardrail_name in opted_out_global_guardrails
|
||||
):
|
||||
return False
|
||||
|
||||
if self.default_on is True and disable_global_guardrail is not True:
|
||||
|
||||
@ -874,9 +874,9 @@ class CustomLogger: # https://docs.litellm.ai/docs/observability/custom_callbac
|
||||
model_response_dict = model_response.model_dump()
|
||||
standard_logging_object_copy["response"] = model_response_dict
|
||||
|
||||
model_call_details_copy[
|
||||
"standard_logging_object"
|
||||
] = standard_logging_object_copy
|
||||
model_call_details_copy["standard_logging_object"] = (
|
||||
standard_logging_object_copy
|
||||
)
|
||||
return model_call_details_copy
|
||||
|
||||
async def get_proxy_server_request_from_cold_storage_with_object_key(
|
||||
|
||||
@ -349,9 +349,9 @@ class DataDogLLMObsLogger(CustomBatchLogger):
|
||||
|
||||
if standard_logging_payload.get("status") == "failure":
|
||||
# Try to get structured error information first
|
||||
error_information: Optional[
|
||||
StandardLoggingPayloadErrorInformation
|
||||
] = standard_logging_payload.get("error_information")
|
||||
error_information: Optional[StandardLoggingPayloadErrorInformation] = (
|
||||
standard_logging_payload.get("error_information")
|
||||
)
|
||||
|
||||
if error_information:
|
||||
error_info = DDLLMObsError(
|
||||
@ -621,9 +621,9 @@ class DataDogLLMObsLogger(CustomBatchLogger):
|
||||
latency_metrics["litellm_overhead_time_ms"] = litellm_overhead_ms
|
||||
|
||||
# Guardrail overhead latency
|
||||
guardrail_info: Optional[
|
||||
list[StandardLoggingGuardrailInformation]
|
||||
] = standard_logging_payload.get("guardrail_information")
|
||||
guardrail_info: Optional[list[StandardLoggingGuardrailInformation]] = (
|
||||
standard_logging_payload.get("guardrail_information")
|
||||
)
|
||||
if guardrail_info is not None:
|
||||
total_duration = 0.0
|
||||
for info in guardrail_info:
|
||||
@ -793,15 +793,15 @@ class DataDogLLMObsLogger(CustomBatchLogger):
|
||||
if function_arguments:
|
||||
# Store arguments as JSON string for Datadog
|
||||
if isinstance(function_arguments, str):
|
||||
kv_pairs[
|
||||
f"tool_calls.{idx}.function.arguments"
|
||||
] = function_arguments
|
||||
kv_pairs[f"tool_calls.{idx}.function.arguments"] = (
|
||||
function_arguments
|
||||
)
|
||||
else:
|
||||
import json
|
||||
|
||||
kv_pairs[
|
||||
f"tool_calls.{idx}.function.arguments"
|
||||
] = json.dumps(function_arguments)
|
||||
kv_pairs[f"tool_calls.{idx}.function.arguments"] = (
|
||||
json.dumps(function_arguments)
|
||||
)
|
||||
except (KeyError, TypeError, ValueError) as e:
|
||||
verbose_logger.debug(
|
||||
f"DataDogLLMObs: Error processing tool call {idx}: {str(e)}"
|
||||
|
||||
@ -150,9 +150,9 @@ class GCSBucketBase(CustomBatchLogger):
|
||||
if kwargs is None:
|
||||
kwargs = {}
|
||||
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = kwargs.get("standard_callback_dynamic_params", None)
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
kwargs.get("standard_callback_dynamic_params", None)
|
||||
)
|
||||
|
||||
bucket_name: str
|
||||
path_service_account: Optional[str]
|
||||
|
||||
@ -162,7 +162,11 @@ class HumanloopLogger(CustomLogger):
|
||||
prompt_version: Optional[int] = None,
|
||||
ignore_prompt_manager_model: Optional[bool] = False,
|
||||
ignore_prompt_manager_optional_params: Optional[bool] = False,
|
||||
) -> Tuple[str, List[AllMessageValues], dict,]:
|
||||
) -> Tuple[
|
||||
str,
|
||||
List[AllMessageValues],
|
||||
dict,
|
||||
]:
|
||||
humanloop_api_key = dynamic_callback_params.get(
|
||||
"humanloop_api_key"
|
||||
) or get_secret_str("HUMANLOOP_API_KEY")
|
||||
|
||||
@ -572,9 +572,9 @@ class LangFuseLogger:
|
||||
# we clean out all extra litellm metadata params before logging
|
||||
clean_metadata: Dict[str, Any] = {}
|
||||
if prompt_management_metadata is not None:
|
||||
clean_metadata[
|
||||
"prompt_management_metadata"
|
||||
] = prompt_management_metadata
|
||||
clean_metadata["prompt_management_metadata"] = (
|
||||
prompt_management_metadata
|
||||
)
|
||||
if isinstance(metadata, dict):
|
||||
for key, value in metadata.items():
|
||||
# generate langfuse tags - Default Tags sent to Langfuse from LiteLLM Proxy
|
||||
|
||||
@ -86,9 +86,7 @@ class LangFuseHandler:
|
||||
if globalLangfuseLogger is not None:
|
||||
return globalLangfuseLogger
|
||||
|
||||
credentials_dict: Dict[
|
||||
str, Any
|
||||
] = (
|
||||
credentials_dict: Dict[str, Any] = (
|
||||
{}
|
||||
) # the global langfuse logger uses Environment Variables, there are no dynamic credentials
|
||||
globalLangfuseLogger = in_memory_dynamic_logger_cache.get_cache(
|
||||
|
||||
@ -190,7 +190,11 @@ class LangfusePromptManagement(LangFuseLogger, PromptManagementBase, CustomLogge
|
||||
prompt_version: Optional[int] = None,
|
||||
ignore_prompt_manager_model: Optional[bool] = False,
|
||||
ignore_prompt_manager_optional_params: Optional[bool] = False,
|
||||
) -> Tuple[str, List[AllMessageValues], dict,]:
|
||||
) -> Tuple[
|
||||
str,
|
||||
List[AllMessageValues],
|
||||
dict,
|
||||
]:
|
||||
return self.get_chat_completion_prompt(
|
||||
model,
|
||||
messages,
|
||||
|
||||
@ -83,9 +83,9 @@ class LangsmithLogger(CustomBatchLogger):
|
||||
if _batch_size:
|
||||
self.batch_size = int(_batch_size)
|
||||
self.log_queue: List[LangsmithQueueObject] = []
|
||||
self._flush_task: Optional[
|
||||
asyncio.Task[Any]
|
||||
] = self._start_periodic_flush_task()
|
||||
self._flush_task: Optional[asyncio.Task[Any]] = (
|
||||
self._start_periodic_flush_task()
|
||||
)
|
||||
|
||||
def _start_periodic_flush_task(self) -> Optional[asyncio.Task[Any]]:
|
||||
"""Start the periodic flush task only when an event loop is already running."""
|
||||
@ -501,9 +501,9 @@ class LangsmithLogger(CustomBatchLogger):
|
||||
return log_queue_by_credentials
|
||||
|
||||
def _get_sampling_rate_to_use_for_request(self, kwargs: Dict[str, Any]) -> float:
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = kwargs.get("standard_callback_dynamic_params", None)
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
kwargs.get("standard_callback_dynamic_params", None)
|
||||
)
|
||||
sampling_rate: float = self.sampling_rate
|
||||
if standard_callback_dynamic_params is not None:
|
||||
_sampling_rate = standard_callback_dynamic_params.get(
|
||||
@ -523,9 +523,9 @@ class LangsmithLogger(CustomBatchLogger):
|
||||
|
||||
Otherwise, use the default credentials.
|
||||
"""
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = kwargs.get("standard_callback_dynamic_params", None)
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
kwargs.get("standard_callback_dynamic_params", None)
|
||||
)
|
||||
if standard_callback_dynamic_params is not None:
|
||||
credentials = self.get_credentials_from_env(
|
||||
langsmith_api_key=standard_callback_dynamic_params.get(
|
||||
|
||||
@ -25,9 +25,9 @@ class MockClientConfig:
|
||||
default_latency_ms: int = 100 # Default mock latency in milliseconds
|
||||
default_status_code: int = 200 # Default HTTP status code
|
||||
default_json_data: Optional[Dict] = None # Default JSON response data
|
||||
url_matchers: Optional[
|
||||
List[str]
|
||||
] = None # List of strings to match in URLs (e.g., ["storage.googleapis.com"])
|
||||
url_matchers: Optional[List[str]] = (
|
||||
None # List of strings to match in URLs (e.g., ["storage.googleapis.com"])
|
||||
)
|
||||
patch_async_handler: bool = True # Whether to patch AsyncHTTPHandler.post
|
||||
patch_sync_client: bool = False # Whether to patch httpx.Client.post
|
||||
patch_http_handler: bool = (
|
||||
|
||||
@ -655,9 +655,9 @@ class OpenTelemetry(CustomLogger):
|
||||
|
||||
def _get_dynamic_otel_headers_from_kwargs(self, kwargs) -> Optional[dict]:
|
||||
"""Extract dynamic headers from kwargs if available."""
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = kwargs.get("standard_callback_dynamic_params")
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
kwargs.get("standard_callback_dynamic_params")
|
||||
)
|
||||
|
||||
if not standard_callback_dynamic_params:
|
||||
return None
|
||||
|
||||
@ -349,9 +349,9 @@ class PostHogLogger(CustomBatchLogger):
|
||||
Returns:
|
||||
tuple[str, str]: (api_key, api_url)
|
||||
"""
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = kwargs.get("standard_callback_dynamic_params", None)
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
kwargs.get("standard_callback_dynamic_params", None)
|
||||
)
|
||||
|
||||
if standard_callback_dynamic_params is not None:
|
||||
api_key = (
|
||||
|
||||
@ -76,7 +76,9 @@ class PrometheusLogger(CustomLogger):
|
||||
|
||||
_custom_buckets = litellm.prometheus_latency_buckets
|
||||
self.latency_buckets = (
|
||||
tuple(_custom_buckets) if _custom_buckets is not None else LATENCY_BUCKETS
|
||||
tuple(_custom_buckets)
|
||||
if _custom_buckets is not None
|
||||
else LATENCY_BUCKETS
|
||||
)
|
||||
|
||||
# Create metric factory functions
|
||||
@ -1100,9 +1102,11 @@ class PrometheusLogger(CustomLogger):
|
||||
),
|
||||
client_ip=standard_logging_payload["metadata"].get("requester_ip_address"),
|
||||
user_agent=standard_logging_payload["metadata"].get("user_agent"),
|
||||
stream=str(standard_logging_payload.get("stream"))
|
||||
if litellm.prometheus_emit_stream_label
|
||||
else None,
|
||||
stream=(
|
||||
str(standard_logging_payload.get("stream"))
|
||||
if litellm.prometheus_emit_stream_label
|
||||
else None
|
||||
),
|
||||
)
|
||||
|
||||
if (
|
||||
@ -1781,9 +1785,11 @@ class PrometheusLogger(CustomLogger):
|
||||
client_ip=_metadata.get("requester_ip_address"),
|
||||
user_agent=_metadata.get("user_agent"),
|
||||
model_id=model_id,
|
||||
stream=str(request_data.get("stream"))
|
||||
if litellm.prometheus_emit_stream_label
|
||||
else None,
|
||||
stream=(
|
||||
str(request_data.get("stream"))
|
||||
if litellm.prometheus_emit_stream_label
|
||||
else None
|
||||
),
|
||||
)
|
||||
_label_ctx = PrometheusLabelFactoryContext(enum_values)
|
||||
PrometheusLogger._inc_labeled_counter(
|
||||
@ -2109,9 +2115,9 @@ class PrometheusLogger(CustomLogger):
|
||||
):
|
||||
try:
|
||||
verbose_logger.debug("setting remaining tokens requests metric")
|
||||
standard_logging_payload: Optional[
|
||||
StandardLoggingPayload
|
||||
] = request_kwargs.get("standard_logging_object")
|
||||
standard_logging_payload: Optional[StandardLoggingPayload] = (
|
||||
request_kwargs.get("standard_logging_object")
|
||||
)
|
||||
|
||||
if standard_logging_payload is None:
|
||||
return
|
||||
@ -2745,9 +2751,7 @@ class PrometheusLogger(CustomLogger):
|
||||
)
|
||||
return
|
||||
|
||||
async def fetch_keys(
|
||||
page_size: int, page: int
|
||||
) -> Tuple[
|
||||
async def fetch_keys(page_size: int, page: int) -> Tuple[
|
||||
List[Union[str, UserAPIKeyAuth, LiteLLM_DeletedVerificationToken]],
|
||||
Optional[int],
|
||||
]:
|
||||
@ -2937,9 +2941,11 @@ class PrometheusLogger(CustomLogger):
|
||||
org_alias=org.organization_alias or "",
|
||||
spend=org.spend or 0.0,
|
||||
max_budget=budget_table.max_budget if budget_table else None,
|
||||
budget_reset_at=getattr(budget_table, "budget_reset_at", None)
|
||||
if budget_table
|
||||
else None,
|
||||
budget_reset_at=(
|
||||
getattr(budget_table, "budget_reset_at", None)
|
||||
if budget_table
|
||||
else None
|
||||
),
|
||||
)
|
||||
|
||||
async def _set_team_budget_metrics_after_api_request(
|
||||
@ -3420,10 +3426,10 @@ class PrometheusLogger(CustomLogger):
|
||||
"""
|
||||
from litellm.constants import PROMETHEUS_BUDGET_METRICS_REFRESH_INTERVAL_MINUTES
|
||||
|
||||
prometheus_loggers: List[
|
||||
CustomLogger
|
||||
] = litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=PrometheusLogger
|
||||
prometheus_loggers: List[CustomLogger] = (
|
||||
litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=PrometheusLogger
|
||||
)
|
||||
)
|
||||
# we need to get the initialized prometheus logger instance(s) and call logger.initialize_remaining_budget_metrics() on them
|
||||
verbose_logger.debug("found %s prometheus loggers", len(prometheus_loggers))
|
||||
|
||||
@ -38,7 +38,9 @@ class PrometheusServicesLogger:
|
||||
|
||||
_custom_buckets = litellm.prometheus_latency_buckets
|
||||
self.latency_buckets = (
|
||||
tuple(_custom_buckets) if _custom_buckets is not None else LATENCY_BUCKETS
|
||||
tuple(_custom_buckets)
|
||||
if _custom_buckets is not None
|
||||
else LATENCY_BUCKETS
|
||||
)
|
||||
|
||||
self.Histogram = Histogram
|
||||
|
||||
@ -597,9 +597,11 @@ class S3Logger(CustomBatchLogger, BaseAWSLLM):
|
||||
request_url = prepped.url or url
|
||||
|
||||
httpx_client = _get_httpx_client(
|
||||
params={"ssl_verify": self.s3_verify}
|
||||
if self.s3_verify is not None
|
||||
else None
|
||||
params=(
|
||||
{"ssl_verify": self.s3_verify}
|
||||
if self.s3_verify is not None
|
||||
else None
|
||||
)
|
||||
)
|
||||
# Make the request with retry for transient S3 errors (500/503)
|
||||
max_retries = 3
|
||||
|
||||
@ -83,9 +83,11 @@ class VantageLogger(FocusLogger):
|
||||
|
||||
verbose_logger.debug(
|
||||
"VantageLogger initialized (integration_token=%s)",
|
||||
resolved_token[:4] + "***"
|
||||
if resolved_token and len(resolved_token) > 4
|
||||
else "***",
|
||||
(
|
||||
resolved_token[:4] + "***"
|
||||
if resolved_token and len(resolved_token) > 4
|
||||
else "***"
|
||||
),
|
||||
)
|
||||
|
||||
async def initialize_focus_export_job(self) -> None:
|
||||
@ -124,10 +126,10 @@ class VantageLogger(FocusLogger):
|
||||
scheduler: AsyncIOScheduler,
|
||||
) -> None:
|
||||
"""Register the Vantage export job with the provided scheduler."""
|
||||
vantage_loggers: List[
|
||||
CustomLogger
|
||||
] = litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=VantageLogger
|
||||
vantage_loggers: List[CustomLogger] = (
|
||||
litellm.logging_callback_manager.get_custom_loggers_for_type(
|
||||
callback_type=VantageLogger
|
||||
)
|
||||
)
|
||||
if not vantage_loggers:
|
||||
verbose_logger.debug("No Vantage logger registered; skipping scheduler")
|
||||
|
||||
@ -88,12 +88,12 @@ class VectorStorePreCallHook(CustomLogger):
|
||||
pass
|
||||
|
||||
# Use database fallback to ensure synchronization across instances
|
||||
vector_stores_to_run: List[
|
||||
LiteLLM_ManagedVectorStore
|
||||
] = await litellm.vector_store_registry.pop_vector_stores_to_run_with_db_fallback(
|
||||
non_default_params=non_default_params,
|
||||
tools=tools,
|
||||
prisma_client=prisma_client,
|
||||
vector_stores_to_run: List[LiteLLM_ManagedVectorStore] = (
|
||||
await litellm.vector_store_registry.pop_vector_stores_to_run_with_db_fallback(
|
||||
non_default_params=non_default_params,
|
||||
tools=tools,
|
||||
prisma_client=prisma_client,
|
||||
)
|
||||
)
|
||||
|
||||
if not vector_stores_to_run:
|
||||
@ -147,9 +147,9 @@ class VectorStorePreCallHook(CustomLogger):
|
||||
|
||||
# Store search results as-is (already in OpenAI-compatible format)
|
||||
if litellm_logging_obj and all_search_results:
|
||||
litellm_logging_obj.model_call_details[
|
||||
"search_results"
|
||||
] = all_search_results
|
||||
litellm_logging_obj.model_call_details["search_results"] = (
|
||||
all_search_results
|
||||
)
|
||||
|
||||
return model, modified_messages, non_default_params
|
||||
|
||||
@ -208,9 +208,9 @@ class VectorStorePreCallHook(CustomLogger):
|
||||
Returns:
|
||||
Modified list of messages with context appended
|
||||
"""
|
||||
search_response_data: Optional[
|
||||
List[VectorStoreSearchResult]
|
||||
] = search_response.get("data")
|
||||
search_response_data: Optional[List[VectorStoreSearchResult]] = (
|
||||
search_response.get("data")
|
||||
)
|
||||
if not search_response_data:
|
||||
return messages
|
||||
|
||||
@ -268,9 +268,9 @@ class VectorStorePreCallHook(CustomLogger):
|
||||
)
|
||||
|
||||
# Get search results from model_call_details (already in OpenAI format)
|
||||
search_results: Optional[
|
||||
List[VectorStoreSearchResponse]
|
||||
] = litellm_logging_obj.model_call_details.get("search_results")
|
||||
search_results: Optional[List[VectorStoreSearchResponse]] = (
|
||||
litellm_logging_obj.model_call_details.get("search_results")
|
||||
)
|
||||
|
||||
verbose_logger.debug(f"Search results found: {search_results is not None}")
|
||||
|
||||
@ -328,9 +328,9 @@ class VectorStorePreCallHook(CustomLogger):
|
||||
)
|
||||
|
||||
# Get search results from model_call_details (already in OpenAI format)
|
||||
search_results: Optional[
|
||||
List[VectorStoreSearchResponse]
|
||||
] = request_data.get("search_results")
|
||||
search_results: Optional[List[VectorStoreSearchResponse]] = (
|
||||
request_data.get("search_results")
|
||||
)
|
||||
|
||||
verbose_logger.debug(
|
||||
f"Search results found for streaming chunk: {search_results is not None}"
|
||||
|
||||
@ -3,6 +3,7 @@ WebSearch Tool Transformation
|
||||
|
||||
Transforms between Anthropic/OpenAI tool_use format and LiteLLM search format.
|
||||
"""
|
||||
|
||||
import json
|
||||
from typing import Any, Dict, List, Optional, Tuple, Union
|
||||
|
||||
@ -326,9 +327,11 @@ class WebSearchTransformation:
|
||||
"type": "function",
|
||||
"function": {
|
||||
"name": tc["name"],
|
||||
"arguments": json.dumps(tc["input"])
|
||||
if isinstance(tc["input"], dict)
|
||||
else str(tc["input"]),
|
||||
"arguments": (
|
||||
json.dumps(tc["input"])
|
||||
if isinstance(tc["input"], dict)
|
||||
else str(tc["input"])
|
||||
),
|
||||
},
|
||||
}
|
||||
for tc in tool_calls
|
||||
|
||||
@ -21,8 +21,7 @@ try:
|
||||
# contains a (known) object attribute
|
||||
object: Literal["chat.completion", "edit", "text_completion"]
|
||||
|
||||
def __getitem__(self, key: K) -> V:
|
||||
... # noqa
|
||||
def __getitem__(self, key: K) -> V: ... # noqa
|
||||
|
||||
def get(self, key: K, default: Optional[V] = None) -> Optional[V]: # noqa
|
||||
... # pragma: no cover
|
||||
|
||||
@ -45,10 +45,10 @@ class LiteLLMResponsesInteractionsConfig:
|
||||
|
||||
# Transform input
|
||||
if input is not None:
|
||||
responses_request[
|
||||
"input"
|
||||
] = LiteLLMResponsesInteractionsConfig._transform_interactions_input_to_responses_input(
|
||||
input
|
||||
responses_request["input"] = (
|
||||
LiteLLMResponsesInteractionsConfig._transform_interactions_input_to_responses_input(
|
||||
input
|
||||
)
|
||||
)
|
||||
|
||||
# Transform system_instruction -> instructions
|
||||
|
||||
@ -26,9 +26,9 @@ if custom_cache_dir:
|
||||
else:
|
||||
cache_dir = filename
|
||||
|
||||
os.environ[
|
||||
"TIKTOKEN_CACHE_DIR"
|
||||
] = cache_dir # use local copy of tiktoken b/c of - https://github.com/BerriAI/litellm/issues/1071
|
||||
os.environ["TIKTOKEN_CACHE_DIR"] = (
|
||||
cache_dir # use local copy of tiktoken b/c of - https://github.com/BerriAI/litellm/issues/1071
|
||||
)
|
||||
|
||||
import tiktoken
|
||||
import time
|
||||
|
||||
@ -2460,7 +2460,9 @@ def exception_type( # type: ignore # noqa: PLR0915
|
||||
setattr(e, "litellm_response_headers", litellm_response_headers)
|
||||
raise e # it's already mapped
|
||||
raised_exc = APIConnectionError(
|
||||
message="{}\n{}".format(original_exception, _redact_string(traceback.format_exc())),
|
||||
message="{}\n{}".format(
|
||||
original_exception, _redact_string(traceback.format_exc())
|
||||
),
|
||||
llm_provider="",
|
||||
model="",
|
||||
)
|
||||
|
||||
@ -56,8 +56,9 @@ def pick_cheapest_chat_models_from_llm_provider(custom_llm_provider: str, n=1):
|
||||
continue
|
||||
if model_info.get("mode") != "chat":
|
||||
continue
|
||||
_cost = (model_info.get("input_cost_per_token") or 0.0) + (model_info.get(
|
||||
"output_cost_per_token") or 0.0)
|
||||
_cost = (model_info.get("input_cost_per_token") or 0.0) + (
|
||||
model_info.get("output_cost_per_token") or 0.0
|
||||
)
|
||||
model_costs.append((model, _cost))
|
||||
|
||||
# Sort by cost (ascending)
|
||||
|
||||
@ -596,9 +596,9 @@ def convert_to_model_response_object( # noqa: PLR0915
|
||||
provider_specific_fields["thinking_blocks"] = thinking_blocks
|
||||
|
||||
if reasoning_content:
|
||||
provider_specific_fields[
|
||||
"reasoning_content"
|
||||
] = reasoning_content
|
||||
provider_specific_fields["reasoning_content"] = (
|
||||
reasoning_content
|
||||
)
|
||||
|
||||
message = Message(
|
||||
content=content,
|
||||
@ -787,9 +787,9 @@ def convert_to_model_response_object( # noqa: PLR0915
|
||||
# tracking without exposing it in the response body. Must be set
|
||||
# after hidden_params assignment to avoid being overwritten.
|
||||
if "_audio_transcription_duration" in response_object:
|
||||
model_response_object._hidden_params[
|
||||
"audio_transcription_duration"
|
||||
] = response_object["_audio_transcription_duration"]
|
||||
model_response_object._hidden_params["audio_transcription_duration"] = (
|
||||
response_object["_audio_transcription_duration"]
|
||||
)
|
||||
|
||||
if _response_headers is not None:
|
||||
model_response_object._response_headers = _response_headers
|
||||
|
||||
@ -1393,10 +1393,10 @@ def convert_to_gemini_tool_call_invoke(
|
||||
if tool_calls is not None:
|
||||
for idx, tool in enumerate(tool_calls):
|
||||
if "function" in tool:
|
||||
gemini_function_call: Optional[
|
||||
VertexFunctionCall
|
||||
] = _gemini_tool_call_invoke_helper(
|
||||
function_call_params=tool["function"]
|
||||
gemini_function_call: Optional[VertexFunctionCall] = (
|
||||
_gemini_tool_call_invoke_helper(
|
||||
function_call_params=tool["function"]
|
||||
)
|
||||
)
|
||||
if gemini_function_call is not None:
|
||||
part_dict: VertexPartType = {
|
||||
@ -1574,9 +1574,7 @@ def convert_to_gemini_tool_call_result( # noqa: PLR0915
|
||||
file_data = (
|
||||
file_content.get("file_data", "")
|
||||
if isinstance(file_content, dict)
|
||||
else file_content
|
||||
if isinstance(file_content, str)
|
||||
else ""
|
||||
else file_content if isinstance(file_content, str) else ""
|
||||
)
|
||||
|
||||
if file_data:
|
||||
@ -2081,9 +2079,9 @@ def _sanitize_empty_text_content(
|
||||
if isinstance(content, str):
|
||||
if not content or not content.strip():
|
||||
message = cast(AllMessageValues, dict(message)) # Make a copy
|
||||
message[
|
||||
"content"
|
||||
] = "[System: Empty message content sanitised to satisfy protocol]"
|
||||
message["content"] = (
|
||||
"[System: Empty message content sanitised to satisfy protocol]"
|
||||
)
|
||||
verbose_logger.debug(
|
||||
f"_sanitize_empty_text_content: Replaced empty text content in {message.get('role')} message"
|
||||
)
|
||||
@ -2423,9 +2421,9 @@ def anthropic_messages_pt( # noqa: PLR0915
|
||||
# Convert ChatCompletionImageUrlObject to dict if needed
|
||||
image_url_value = m["image_url"]
|
||||
if isinstance(image_url_value, str):
|
||||
image_url_input: Union[
|
||||
str, dict[str, Any]
|
||||
] = image_url_value
|
||||
image_url_input: Union[str, dict[str, Any]] = (
|
||||
image_url_value
|
||||
)
|
||||
else:
|
||||
# ChatCompletionImageUrlObject or dict case - convert to dict
|
||||
image_url_input = {
|
||||
@ -2452,9 +2450,9 @@ def anthropic_messages_pt( # noqa: PLR0915
|
||||
)
|
||||
|
||||
if "cache_control" in _content_element:
|
||||
_anthropic_content_element[
|
||||
"cache_control"
|
||||
] = _content_element["cache_control"]
|
||||
_anthropic_content_element["cache_control"] = (
|
||||
_content_element["cache_control"]
|
||||
)
|
||||
user_content.append(_anthropic_content_element)
|
||||
elif m.get("type", "") == "text":
|
||||
m = cast(ChatCompletionTextObject, m)
|
||||
@ -2514,9 +2512,9 @@ def anthropic_messages_pt( # noqa: PLR0915
|
||||
)
|
||||
|
||||
if "cache_control" in _content_element:
|
||||
_anthropic_content_text_element[
|
||||
"cache_control"
|
||||
] = _content_element["cache_control"]
|
||||
_anthropic_content_text_element["cache_control"] = (
|
||||
_content_element["cache_control"]
|
||||
)
|
||||
|
||||
user_content.append(_anthropic_content_text_element)
|
||||
|
||||
@ -2649,9 +2647,9 @@ def anthropic_messages_pt( # noqa: PLR0915
|
||||
original_content_element=dict(assistant_content_block),
|
||||
)
|
||||
if "cache_control" in _content_element:
|
||||
_anthropic_text_content_element[
|
||||
"cache_control"
|
||||
] = _content_element["cache_control"]
|
||||
_anthropic_text_content_element["cache_control"] = (
|
||||
_content_element["cache_control"]
|
||||
)
|
||||
text_element = _anthropic_text_content_element
|
||||
|
||||
# Interleave: each thinking block precedes its server tool group.
|
||||
@ -2811,9 +2809,9 @@ def anthropic_messages_pt( # noqa: PLR0915
|
||||
)
|
||||
|
||||
if "cache_control" in _content_element:
|
||||
_anthropic_text_content_element[
|
||||
"cache_control"
|
||||
] = _content_element["cache_control"]
|
||||
_anthropic_text_content_element["cache_control"] = (
|
||||
_content_element["cache_control"]
|
||||
)
|
||||
|
||||
assistant_content.append(_anthropic_text_content_element)
|
||||
|
||||
|
||||
@ -199,12 +199,12 @@ class RealTimeStreaming:
|
||||
if self.input_messages:
|
||||
self.logging_obj.model_call_details["messages"] = self.input_messages
|
||||
if self.session_tools or self.tool_calls:
|
||||
self.logging_obj.model_call_details[
|
||||
"realtime_tools"
|
||||
] = self.session_tools
|
||||
self.logging_obj.model_call_details[
|
||||
"realtime_tool_calls"
|
||||
] = self.tool_calls
|
||||
self.logging_obj.model_call_details["realtime_tools"] = (
|
||||
self.session_tools
|
||||
)
|
||||
self.logging_obj.model_call_details["realtime_tool_calls"] = (
|
||||
self.tool_calls
|
||||
)
|
||||
## ASYNC LOGGING
|
||||
# Create an event loop for the new thread
|
||||
asyncio.create_task(self.logging_obj.async_success_handler(self.messages))
|
||||
|
||||
@ -285,9 +285,9 @@ def _get_turn_off_message_logging_from_dynamic_params(
|
||||
|
||||
handles boolean and string values of `turn_off_message_logging`
|
||||
"""
|
||||
standard_callback_dynamic_params: Optional[
|
||||
StandardCallbackDynamicParams
|
||||
] = model_call_details.get("standard_callback_dynamic_params", None)
|
||||
standard_callback_dynamic_params: Optional[StandardCallbackDynamicParams] = (
|
||||
model_call_details.get("standard_callback_dynamic_params", None)
|
||||
)
|
||||
if standard_callback_dynamic_params:
|
||||
_turn_off_message_logging = standard_callback_dynamic_params.get(
|
||||
"turn_off_message_logging"
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
Helper for safe JSON loading in LiteLLM.
|
||||
"""
|
||||
|
||||
from typing import Any
|
||||
import json
|
||||
|
||||
|
||||
@ -7,6 +7,7 @@ This ensures we do
|
||||
1. Proper cleanup of Langfuse initialized clients.
|
||||
2. Re-use created langfuse clients.
|
||||
"""
|
||||
|
||||
import hashlib
|
||||
import json
|
||||
from typing import Any, Optional
|
||||
|
||||
@ -163,9 +163,9 @@ class ChunkProcessor:
|
||||
self, tool_call_chunks: List[Dict[str, Any]]
|
||||
) -> List[ChatCompletionMessageToolCall]:
|
||||
tool_calls_list: List[ChatCompletionMessageToolCall] = []
|
||||
tool_call_map: Dict[
|
||||
int, Dict[str, Any]
|
||||
] = {} # Map to store tool calls by index
|
||||
tool_call_map: Dict[int, Dict[str, Any]] = (
|
||||
{}
|
||||
) # Map to store tool calls by index
|
||||
|
||||
for chunk in tool_call_chunks:
|
||||
choices = chunk["choices"]
|
||||
@ -646,12 +646,12 @@ class ChunkProcessor:
|
||||
web_search_requests: Optional[int] = calculated_usage_per_chunk[
|
||||
"web_search_requests"
|
||||
]
|
||||
completion_tokens_details: Optional[
|
||||
CompletionTokensDetails
|
||||
] = calculated_usage_per_chunk["completion_tokens_details"]
|
||||
prompt_tokens_details: Optional[
|
||||
PromptTokensDetailsWrapper
|
||||
] = calculated_usage_per_chunk["prompt_tokens_details"]
|
||||
completion_tokens_details: Optional[CompletionTokensDetails] = (
|
||||
calculated_usage_per_chunk["completion_tokens_details"]
|
||||
)
|
||||
prompt_tokens_details: Optional[PromptTokensDetailsWrapper] = (
|
||||
calculated_usage_per_chunk["prompt_tokens_details"]
|
||||
)
|
||||
|
||||
try:
|
||||
returned_usage.prompt_tokens = prompt_tokens or token_counter(
|
||||
|
||||
@ -127,9 +127,9 @@ class CustomStreamWrapper:
|
||||
|
||||
self.system_fingerprint: Optional[str] = None
|
||||
self.received_finish_reason: Optional[str] = None
|
||||
self.intermittent_finish_reason: Optional[
|
||||
str
|
||||
] = None # finish reasons that show up mid-stream
|
||||
self.intermittent_finish_reason: Optional[str] = (
|
||||
None # finish reasons that show up mid-stream
|
||||
)
|
||||
self.special_tokens = [
|
||||
"<|assistant|>",
|
||||
"<|system|>",
|
||||
@ -1524,9 +1524,9 @@ class CustomStreamWrapper:
|
||||
t.function.arguments = ""
|
||||
_json_delta = delta.model_dump()
|
||||
if "role" not in _json_delta or _json_delta["role"] is None:
|
||||
_json_delta[
|
||||
"role"
|
||||
] = "assistant" # mistral's api returns role as None
|
||||
_json_delta["role"] = (
|
||||
"assistant" # mistral's api returns role as None
|
||||
)
|
||||
if "tool_calls" in _json_delta and isinstance(
|
||||
_json_delta["tool_calls"], list
|
||||
):
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
A2A (Agent-to-Agent) Protocol Provider for LiteLLM
|
||||
"""
|
||||
|
||||
from .chat.transformation import A2AConfig
|
||||
|
||||
__all__ = ["A2AConfig"]
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
A2A Chat Completion Implementation
|
||||
"""
|
||||
|
||||
from .transformation import A2AConfig
|
||||
|
||||
__all__ = ["A2AConfig"]
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
A2A Streaming Response Iterator
|
||||
"""
|
||||
|
||||
from typing import Optional, Union
|
||||
|
||||
from litellm.llms.base_llm.base_model_iterator import BaseModelResponseIterator
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
A2A Protocol Transformation for LiteLLM
|
||||
"""
|
||||
|
||||
import uuid
|
||||
from typing import Any, Dict, Iterator, List, Optional, Union
|
||||
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
Common utilities for A2A (Agent-to-Agent) Protocol
|
||||
"""
|
||||
|
||||
from typing import Any, Dict, List
|
||||
|
||||
from pydantic import BaseModel
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
"""
|
||||
Translate from OpenAI's `/v1/chat/completions` to Amazon Nova's `/v1/chat/completions`
|
||||
"""
|
||||
|
||||
from typing import Any, List, Optional, Tuple
|
||||
|
||||
import httpx
|
||||
|
||||
@ -229,12 +229,12 @@ class AnthropicBatchesConfig(BaseBatchesConfig):
|
||||
completed_at=ended_at if processing_status == "ended" else None,
|
||||
failed_at=None,
|
||||
expired_at=archived_at if archived_at else None,
|
||||
cancelling_at=cancel_initiated_at
|
||||
if processing_status == "canceling"
|
||||
else None,
|
||||
cancelled_at=ended_at
|
||||
if processing_status == "canceling" and ended_at
|
||||
else None,
|
||||
cancelling_at=(
|
||||
cancel_initiated_at if processing_status == "canceling" else None
|
||||
),
|
||||
cancelled_at=(
|
||||
ended_at if processing_status == "canceling" and ended_at else None
|
||||
),
|
||||
request_counts=request_counts,
|
||||
metadata={},
|
||||
)
|
||||
|
||||
@ -99,9 +99,9 @@ class AnthropicMessagesHandler(BaseTranslation):
|
||||
|
||||
texts_to_check: List[str] = []
|
||||
images_to_check: List[str] = []
|
||||
tools_to_check: List[
|
||||
ChatCompletionToolParam
|
||||
] = chat_completion_compatible_request.get("tools", [])
|
||||
tools_to_check: List[ChatCompletionToolParam] = (
|
||||
chat_completion_compatible_request.get("tools", [])
|
||||
)
|
||||
task_mappings: List[Tuple[int, Optional[int]]] = []
|
||||
# Track (message_index, content_index) for each text
|
||||
# content_index is None for string content, int for list content
|
||||
|
||||
@ -593,9 +593,7 @@ class ModelResponseIterator:
|
||||
speed=self.speed,
|
||||
)
|
||||
|
||||
def _content_block_delta_helper(
|
||||
self, chunk: dict
|
||||
) -> Tuple[
|
||||
def _content_block_delta_helper(self, chunk: dict) -> Tuple[
|
||||
str,
|
||||
Optional[ChatCompletionToolCallChunk],
|
||||
List[Union[ChatCompletionThinkingBlock, ChatCompletionRedactedThinkingBlock]],
|
||||
@ -820,9 +818,9 @@ class ModelResponseIterator:
|
||||
tool_input = content_block_start["content_block"].get(
|
||||
"input", {}
|
||||
)
|
||||
self._server_tool_inputs[
|
||||
self._current_server_tool_id
|
||||
] = tool_input
|
||||
self._server_tool_inputs[self._current_server_tool_id] = (
|
||||
tool_input
|
||||
)
|
||||
# Include caller information if present (for programmatic tool calling)
|
||||
if "caller" in content_block_start["content_block"]:
|
||||
caller_data = content_block_start["content_block"]["caller"]
|
||||
@ -843,9 +841,9 @@ class ModelResponseIterator:
|
||||
# Handle compaction blocks
|
||||
# The full content comes in content_block_start
|
||||
self.compaction_blocks.append(content_block_start["content_block"])
|
||||
provider_specific_fields[
|
||||
"compaction_blocks"
|
||||
] = self.compaction_blocks
|
||||
provider_specific_fields["compaction_blocks"] = (
|
||||
self.compaction_blocks
|
||||
)
|
||||
provider_specific_fields["compaction_start"] = {
|
||||
"type": "compaction",
|
||||
"content": content_block_start["content_block"].get(
|
||||
@ -867,9 +865,9 @@ class ModelResponseIterator:
|
||||
self.web_search_results.append(
|
||||
content_block_start["content_block"]
|
||||
)
|
||||
provider_specific_fields[
|
||||
"web_search_results"
|
||||
] = self.web_search_results
|
||||
provider_specific_fields["web_search_results"] = (
|
||||
self.web_search_results
|
||||
)
|
||||
elif content_type == "web_fetch_tool_result":
|
||||
# Capture web_fetch_tool_result for multi-turn reconstruction
|
||||
# The full content comes in content_block_start, not in deltas
|
||||
@ -877,18 +875,18 @@ class ModelResponseIterator:
|
||||
self.web_search_results.append(
|
||||
content_block_start["content_block"]
|
||||
)
|
||||
provider_specific_fields[
|
||||
"web_search_results"
|
||||
] = self.web_search_results
|
||||
provider_specific_fields["web_search_results"] = (
|
||||
self.web_search_results
|
||||
)
|
||||
elif content_type != "tool_search_tool_result":
|
||||
# Handle other tool results (code execution, etc.)
|
||||
# Skip tool_search_tool_result as it's internal metadata
|
||||
self.tool_results.append(content_block_start["content_block"])
|
||||
provider_specific_fields["tool_results"] = self.tool_results
|
||||
# Convert to provider-neutral code_interpreter_results
|
||||
provider_specific_fields[
|
||||
"code_interpreter_results"
|
||||
] = self._build_code_interpreter_results()
|
||||
provider_specific_fields["code_interpreter_results"] = (
|
||||
self._build_code_interpreter_results()
|
||||
)
|
||||
|
||||
elif type_chunk == "content_block_stop":
|
||||
ContentBlockStop(**chunk) # type: ignore
|
||||
@ -945,9 +943,9 @@ class ModelResponseIterator:
|
||||
)
|
||||
if container_id and self.tool_results:
|
||||
self._container_id = container_id
|
||||
provider_specific_fields[
|
||||
"code_interpreter_results"
|
||||
] = self._build_code_interpreter_results()
|
||||
provider_specific_fields["code_interpreter_results"] = (
|
||||
self._build_code_interpreter_results()
|
||||
)
|
||||
elif type_chunk == "message_start":
|
||||
"""
|
||||
Anthropic
|
||||
|
||||
@ -1015,11 +1015,11 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
if mcp_servers:
|
||||
optional_params["mcp_servers"] = mcp_servers
|
||||
elif param == "tool_choice" or param == "parallel_tool_calls":
|
||||
_tool_choice: Optional[
|
||||
AnthropicMessagesToolChoice
|
||||
] = self._map_tool_choice(
|
||||
tool_choice=non_default_params.get("tool_choice"),
|
||||
parallel_tool_use=non_default_params.get("parallel_tool_calls"),
|
||||
_tool_choice: Optional[AnthropicMessagesToolChoice] = (
|
||||
self._map_tool_choice(
|
||||
tool_choice=non_default_params.get("tool_choice"),
|
||||
parallel_tool_use=non_default_params.get("parallel_tool_calls"),
|
||||
)
|
||||
)
|
||||
|
||||
if _tool_choice is not None:
|
||||
@ -1122,9 +1122,9 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
self.map_openai_context_management_to_anthropic(value)
|
||||
)
|
||||
if anthropic_context_management is not None:
|
||||
optional_params[
|
||||
"context_management"
|
||||
] = anthropic_context_management
|
||||
optional_params["context_management"] = (
|
||||
anthropic_context_management
|
||||
)
|
||||
elif param == "speed" and isinstance(value, str):
|
||||
# Pass through Anthropic-specific speed parameter for fast mode
|
||||
optional_params["speed"] = value
|
||||
@ -1198,9 +1198,9 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
text=system_message_block["content"],
|
||||
)
|
||||
if "cache_control" in system_message_block:
|
||||
anthropic_system_message_content[
|
||||
"cache_control"
|
||||
] = system_message_block["cache_control"]
|
||||
anthropic_system_message_content["cache_control"] = (
|
||||
system_message_block["cache_control"]
|
||||
)
|
||||
anthropic_system_message_list.append(
|
||||
anthropic_system_message_content
|
||||
)
|
||||
@ -1224,9 +1224,9 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
)
|
||||
)
|
||||
if "cache_control" in _content:
|
||||
anthropic_system_message_content[
|
||||
"cache_control"
|
||||
] = _content["cache_control"]
|
||||
anthropic_system_message_content["cache_control"] = (
|
||||
_content["cache_control"]
|
||||
)
|
||||
|
||||
anthropic_system_message_list.append(
|
||||
anthropic_system_message_content
|
||||
@ -1569,9 +1569,7 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
)
|
||||
return _message
|
||||
|
||||
def extract_response_content(
|
||||
self, completion_response: dict
|
||||
) -> Tuple[
|
||||
def extract_response_content(self, completion_response: dict) -> Tuple[
|
||||
str,
|
||||
Optional[List[Any]],
|
||||
Optional[
|
||||
@ -1867,9 +1865,9 @@ class AnthropicConfig(AnthropicModelInfo, BaseConfig):
|
||||
code_interpreter_results = self._build_code_interpreter_results(
|
||||
tool_results, code_by_id, container_id
|
||||
)
|
||||
provider_specific_fields[
|
||||
"code_interpreter_results"
|
||||
] = code_interpreter_results
|
||||
provider_specific_fields["code_interpreter_results"] = (
|
||||
code_interpreter_results
|
||||
)
|
||||
|
||||
container = completion_response.get("container")
|
||||
if container is not None:
|
||||
|
||||
@ -55,9 +55,9 @@ class AnthropicTextConfig(BaseConfig):
|
||||
to pass metadata to anthropic, it's {"user_id": "any-relevant-information"}
|
||||
"""
|
||||
|
||||
max_tokens_to_sample: Optional[
|
||||
int
|
||||
] = litellm.max_tokens # anthropic requires a default
|
||||
max_tokens_to_sample: Optional[int] = (
|
||||
litellm.max_tokens
|
||||
) # anthropic requires a default
|
||||
stop_sequences: Optional[list] = None
|
||||
temperature: Optional[int] = None
|
||||
top_p: Optional[int] = None
|
||||
|
||||
@ -550,9 +550,9 @@ class LiteLLMAnthropicMessagesAdapter:
|
||||
|
||||
## ASSISTANT MESSAGE ##
|
||||
assistant_message_str: Optional[str] = None
|
||||
assistant_content_list: List[
|
||||
Dict[str, Any]
|
||||
] = [] # For content blocks with cache_control
|
||||
assistant_content_list: List[Dict[str, Any]] = (
|
||||
[]
|
||||
) # For content blocks with cache_control
|
||||
has_cache_control_in_text = False
|
||||
tool_calls: List[ChatCompletionAssistantToolCall] = []
|
||||
thinking_blocks: List[
|
||||
@ -595,12 +595,12 @@ class LiteLLMAnthropicMessagesAdapter:
|
||||
function_chunk.get("provider_specific_fields")
|
||||
or {}
|
||||
)
|
||||
provider_specific_fields[
|
||||
"thought_signature"
|
||||
] = signature
|
||||
function_chunk[
|
||||
"provider_specific_fields"
|
||||
] = provider_specific_fields
|
||||
provider_specific_fields["thought_signature"] = (
|
||||
signature
|
||||
)
|
||||
function_chunk["provider_specific_fields"] = (
|
||||
provider_specific_fields
|
||||
)
|
||||
|
||||
tool_call = ChatCompletionAssistantToolCall(
|
||||
id=content.get("id", ""),
|
||||
@ -1340,9 +1340,9 @@ class LiteLLMAnthropicMessagesAdapter:
|
||||
hasattr(usage, "_cache_creation_input_tokens")
|
||||
and usage._cache_creation_input_tokens > 0
|
||||
):
|
||||
anthropic_usage[
|
||||
"cache_creation_input_tokens"
|
||||
] = usage._cache_creation_input_tokens
|
||||
anthropic_usage["cache_creation_input_tokens"] = (
|
||||
usage._cache_creation_input_tokens
|
||||
)
|
||||
if cached_tokens > 0:
|
||||
anthropic_usage["cache_read_input_tokens"] = cached_tokens
|
||||
|
||||
@ -1519,9 +1519,9 @@ class LiteLLMAnthropicMessagesAdapter:
|
||||
hasattr(litellm_usage_chunk, "_cache_creation_input_tokens")
|
||||
and litellm_usage_chunk._cache_creation_input_tokens > 0
|
||||
):
|
||||
usage_delta[
|
||||
"cache_creation_input_tokens"
|
||||
] = litellm_usage_chunk._cache_creation_input_tokens
|
||||
usage_delta["cache_creation_input_tokens"] = (
|
||||
litellm_usage_chunk._cache_creation_input_tokens
|
||||
)
|
||||
if cached_tokens > 0:
|
||||
usage_delta["cache_read_input_tokens"] = cached_tokens
|
||||
else:
|
||||
|
||||
@ -122,7 +122,10 @@ class FakeAnthropicMessagesStreamIterator:
|
||||
content_block_delta = {
|
||||
"type": "content_block_delta",
|
||||
"index": index,
|
||||
"delta": {"type": "input_json_delta", "partial_json": json.dumps(input_data)},
|
||||
"delta": {
|
||||
"type": "input_json_delta",
|
||||
"partial_json": json.dumps(input_data),
|
||||
},
|
||||
}
|
||||
chunks.append(
|
||||
f"event: content_block_delta\ndata: {json.dumps(content_block_delta)}\n\n".encode()
|
||||
|
||||
@ -79,7 +79,9 @@ class AdvisorOrchestrationHandler(MessagesInterceptor):
|
||||
"advisor tool definition must include a 'model' field specifying the advisor model"
|
||||
)
|
||||
_raw_max_uses = advisor_tool.get("max_uses")
|
||||
max_uses: int = ADVISOR_MAX_USES if _raw_max_uses is None else int(_raw_max_uses)
|
||||
max_uses: int = (
|
||||
ADVISOR_MAX_USES if _raw_max_uses is None else int(_raw_max_uses)
|
||||
)
|
||||
# Optional routing overrides for the advisor sub-call (e.g. proxy routing).
|
||||
# If not set in the tool definition, litellm resolves from env vars.
|
||||
advisor_api_key: Optional[str] = advisor_tool.get("api_key")
|
||||
|
||||
@ -39,12 +39,10 @@ class BaseAnthropicMessagesStreamingIterator:
|
||||
# Set completion_start_time so TTFT is calculated from the first
|
||||
# chunk rather than falling back to end_time in async_success_handler.
|
||||
if self.completion_start_time is not None:
|
||||
self.litellm_logging_obj.completion_start_time = (
|
||||
self.litellm_logging_obj.completion_start_time = self.completion_start_time
|
||||
self.litellm_logging_obj.model_call_details["completion_start_time"] = (
|
||||
self.completion_start_time
|
||||
)
|
||||
self.litellm_logging_obj.model_call_details[
|
||||
"completion_start_time"
|
||||
] = self.completion_start_time
|
||||
asyncio.create_task(
|
||||
PassThroughStreamingHandler._route_streaming_logging_to_handler(
|
||||
litellm_logging_obj=self.litellm_logging_obj,
|
||||
|
||||
@ -35,9 +35,9 @@ class AnthropicResponsesStreamWrapper:
|
||||
# Map item_id -> content_block_index so we can stop the right block later
|
||||
self._item_id_to_block_index: Dict[str, int] = {}
|
||||
# Track open function_call items by item_id so we can emit tool_use start
|
||||
self._pending_tool_ids: Dict[
|
||||
str, str
|
||||
] = {} # item_id -> call_id / name accumulator
|
||||
self._pending_tool_ids: Dict[str, str] = (
|
||||
{}
|
||||
) # item_id -> call_id / name accumulator
|
||||
self._sent_message_start = False
|
||||
self._sent_message_stop = False
|
||||
self._chunk_queue: deque = deque()
|
||||
|
||||
@ -337,10 +337,10 @@ class LiteLLMAnthropicToResponsesAPIAdapter:
|
||||
# tool_choice
|
||||
tool_choice = anthropic_request.get("tool_choice")
|
||||
if tool_choice:
|
||||
responses_kwargs[
|
||||
"tool_choice"
|
||||
] = self.translate_tool_choice_to_responses_api(
|
||||
cast(AnthropicMessagesToolChoice, tool_choice)
|
||||
responses_kwargs["tool_choice"] = (
|
||||
self.translate_tool_choice_to_responses_api(
|
||||
cast(AnthropicMessagesToolChoice, tool_choice)
|
||||
)
|
||||
)
|
||||
|
||||
# thinking -> reasoning
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user